I’m working on helping our IDC process to make it work better. Currently, I believe our classification success is at about 50% and the users aren’t real happy about that. I’m super new to IDC and OCR in general so I am playing around with settings trying to understand how it works. I have a request into the Ancora site to see if they have any better docs, but from what I read here, these aren’t going to help me much.
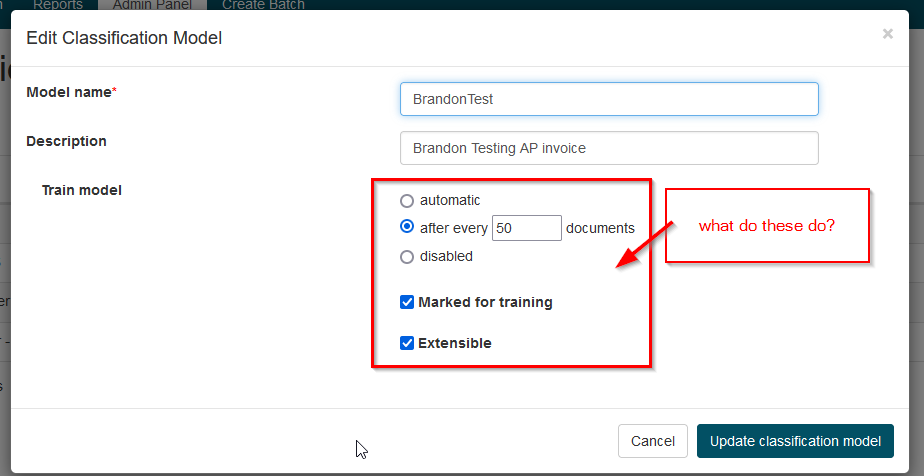
The only real settings that I see on the classification model are these. I don’t really understand what the radio buttons mean. What’s the difference between automatic, and after every x documents? Also what is “Marked for training” and “Extensible” mean?
@Banderson - sorry brother, I don’t have that module - and the Ancora Docs site is tight up on the classification documents. I can search for them, but not see them. Looks to be a few helpful ones based on title.
I think a few other ECM users here have classification - at least I met a few of them in Nashville this year.
Honestly not sure. I can’t get to any docs b/c I’m not licensed. My understanding is that you group by type/vendor and build models based on those groupings - then upload the model and dataset if needed - and IDC will then ‘learn’ from the model.
@Banderson We make drop folders by document type, so it eliminates classification doing that since I don’t own the classification module. I have AP, SOA, SOA EU and packing slips folders and the users drop them. Each user really only has one document type so for them they drop it in “their” folder.
@Banderson Another thing I found was that if myself and another person were training the same document nad making different choices then were were both training and untraining the system so I went to one AP and one Sales Order trainer and we can get to over 90% on a document in as few as three passes. This is on capture, but I would assume it would apply to classificaton.
That’s interesting. I don’t see where I can turn users on or off for the training (I’m making an assumption that training can be updated as new invoice come in through the normal flow). Is that a setting that is not very well named?
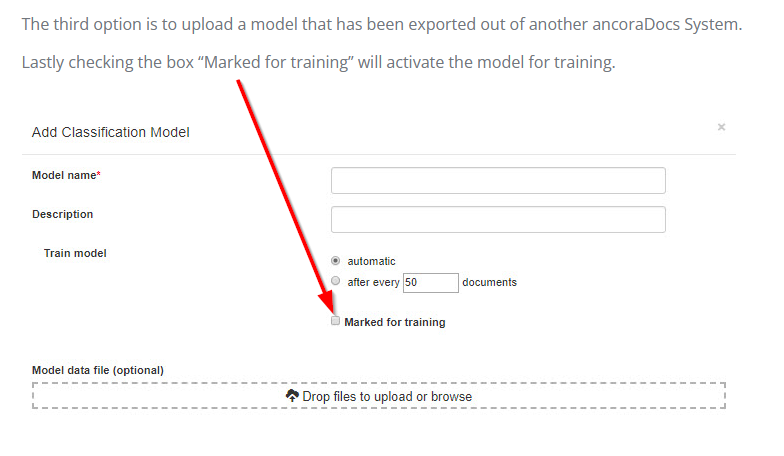
Well, I got into the Ancora website, and it says that the check box “Marked for training” means, that’s when it trains. So the fact that it’s not learning is because that checkbox is off.
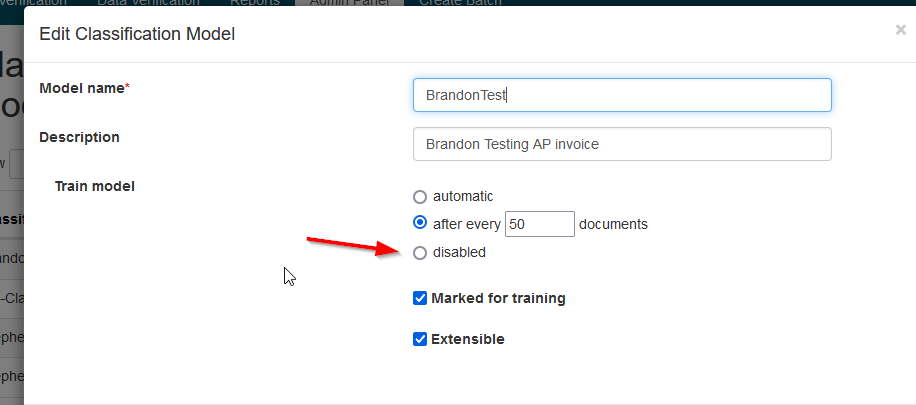
I will say though, in our system it shows an extra radio button and another check box “Extensible”. So one would assume that marked for training means something else because why else would you you have the radio button for disabled?
@Banderson What I mean by training is the IDC mapping of a document field to a location on the form.
As an aside I was told by support that before submitting you should save the batch to save the training. Now even before doing that I had a ton of documents at 100%, so I took it with a grain of salt.
As far as people training. I have four that process AP invoices and three that do SO Automation in ECM, but only one from each group maps all documents in IDC. The other users do not ever log into IDC at all. They are ECM only.
Also there is a utility to delete the training data for a form from a vendor or customer and start over that you can get from support.
I tried to turn on classification tonight and it may not be that I don’t have it but maybe I don’t understand it. I got documents into waiting for class verify, but they are not available in load batch.
It may also be we were too cheap since from what I read the classification and data capture count as a page count, so each document is double dipping. The read the first X pages and the last checkbox is also to save on page counts…
As far as I know, we aren’t even using ECM yet. (That’s what I’m going to be working on to expand). We are just using IDC to package and rename files for a homegrown program to distribute. Honesty I don’t kmeven know if we need the classification step, since it’s always invoices anyways. But that’s the step where it gets stuck.
@Banderson I have to reiterate what Greg is saying here. IDC Training is PER PERSON. You can copy the training from one person to another but each person holds their own training data. This is why Greg does what he does. Now, I’ve talked to a few folks about this and some of them separate the workload by some internal designator - maybe multi-company, or department, or vendor/product - and then never cross over. this allow each of them to have specific training data to the documents they will process.
And if you have multiple people in IDC, I’m now curious about your input method - batch size, name, and collection method. Each of the folks in IDC will be processing a batch and since they have their own training data, it would behoove you to segregate the documents in some manner. Else one user will get 100% accuracy on a document and another user will not - for the same document.
The utility Greg mentioned is a good thing to get a hold of. You can train IDC on a bunch of documents in order to get your feet wet, then delete that data and start again with a good plan for training.
All of this is outside of classification of course and as you said - and I wholeheartedly agree - you might not even need to mess with it. If you are only doing AP, skip classification and get your batches and training set up properly.
So how would that work? If the system gets it all in from one stream, then processes the classification based on the training model, how would it know which users training data to use? It’s not picked up by a user until after the classification has been attempted?
Keep in mind, I’m not even talking about the data capture yet. Just the classification.
@Banderson Let’s step back from the specifics and look at what this process is doing that is only 50% correct. If they are all AP invoices they don’t need classification. Other than mapping fields to xml I am not sure I would push this thru IDC, but I don’t know the process.
On your OCR question, they are just looking for a match to specific data in locations to identify the document that just got processed. If it has one profile in the database that matches at x% or better then it has confidence and will process. If it has two or more profiles that are close then it will defer to a human until it builds a profile that matches at better than the confidence threshold you have set.
In the reports tab there is an accuracy section that will give you detailed numbers of fields it got right or wrong in that pass. Even on a first pass of a brand new invoice IDC can do better than 50% in most cases.
Ok, so vocabulary lesson for me here. I need to understand where the lines are for what products so I know we’re on the same page.
IDC- intelligent data capture.
This classifies the documents (if you have more than one classification)
This also reads the document and will spit out files (XML, CSV, Renamed files, etc) (or is this the OCR part?)
OCR - Optical Character recognition?
Is this part of IDC? Or something separate?
Where does ECM (the prince of acronyms because it’s always followed by formerly known as DocStar) come in?
So I’m learning now that this e-mail inbox that it’s monitoring gets all kinds of other documents (ship tickets, proof of delivery, etc.) So these need to be classified as “Attachments”. So now I’m trying to figure out how that works. I see I can mark them as attachments, but I’m not seeing my (Limited) tests ever show them as attachments. (But I’m probably doing something wrong)
Do you want to get on call and chat? it might be easier.
Process wise - classification can bring the training data ‘up’ one level so that it doesn’t involve the users, or it can just determine ‘type’ and arrange the batch accordingly. At least this is what I’ve gleaned. If you choose to add ‘training data’ to the classification model, it will act as Greg described (geometric template matching algorithm).
IDC is a totally separate program - I call it a pre-processor whereas it’s just a replacement for manual data entry of data elements. And yes - the basis is to convert an image into data - OCR or human entry. The ‘training’ creates the templates of fields and probabilities to help the OCR algorithm be more accurate. It will put out an image and a matching data file whose formats are selectable in the DFD. This output pair can be consumed by ECM into a workflow or simply stored.
Is available in both IDC and ECM. IDC does a really good job using a sort of AI/ML to become more accurate over time. ECM simply uses one of the known OCR engines to process the documents the best it can. We do NOT use the ECM OCR for anything except manually when editing a document (we can discuss that later)
ECM (fka DocStar) - this is the storage mechanism. Send it PDFs and XML and it can store it, workflow it, attach it back to Epicor, send it as an Email, look stuff up in another DB and add more metadata to it - all kinds of stuff can happen with ECM. Plus it has links into Office apps like Outlook and Word, plus a module to link it to Docusign.
Hi, @MikeGross. I believe you made that assertion “IDC Training is PER PERSON” earlier in the year on a different discussion when I first joined this group. That contradicted what my DocStar / Epicor professional services partner told me. But then you (or whomever made that assertion earlier in the year) corrected himself by posting that it looks like the IDC Training is NOT PER PERSON anymore with Epicor IDC now being from ancora.
@Banderson , regarding your original question & screenshot:
We have the radio button set to Automatic and both Marked for training and Extensible are UNCHECKED (not checked).
As most of you know, I do not have Epicor ERP. But I have Epicor IDC and ECM. And I use the IDC Classifier / Classification Modeler heavily. In my opinion, the AI-driven Classification is the best thing about IDC – better than it’s OCR scanning or its quirky, sometimes inconsistent DFD functionality (for another discussion).
I only have 2 Batch Types. One is Service Orders; another is Purchase Orders. For the Service Order batch type, I have over 30 Document Types, each with its own DFD. Most of the 30 DTs are for 1 specific customer; a few of the DTs are set up for multiple customers whose PDF layouts are exactly the same (coming from the same broker) The PDFs for all of my 30 DTs are sent to one e-mail account (i.e. SalesOrderPDFs4IDC@mydomain.com) and the 1 Classification Model for that single Batch Type determines the correct Document Type in almost every instance. The Classification Model only picks the wrong DT only once out of 1000 PDFs . . . usually with a confidence below 90%, causing it to be stuck in the Classification queue.
I have a sample of 40 to 42 PDFs for each of the 30 DTs when I build a new Classification Model. And it takes 2 hours to build the new model.
Additionally, that Service Order batch type also includes about 8 additional Attachment document types. Sometimes the e-mail with the Service Order PDF that we want to scan through IDC includes other attachments (consistently from the 8 types) that should not be OCR scanned nor counted towards our IDC document licensing (per page).
We have a similar situation with AP Invoices for a specific business process scenario where 13 vendors (each with different invoice layouts) send us PDFs where we capture a few more fields than a generic AP invoice under a typical AP Automation. So it’s 1 Batch Type for this subset of AP invoices; 13 Document Types (each with its own DFD); 1 e-mail account (i.e. SpecialAPInvoicePDFs4IDC@mydomain.com). And again the single Classification Model always picks the correct DT (out of 13).
The biggest problem with building a new Classification Model on a Windows server: The tool spawns 5 or 6 or 7 processes (visible in Task Manager on the server) that spike the server’s CPU utilization well over 90% and sometimes spiking at 98 or 99%! About 2 months ago, I had my Epicor Professional Services partner address this with ancora. The response was: The Classification model builder runs stand alone outside of the automated clients, so we can’t throttle it back