We are working diligently to go live, which means we are working fairly regularly in our THIRD environment to tidy up customizations/forms before the big day (March 1). Currently it appears our pilot environment (which I take to mean Pilot and Third/test) is currently undergoing maintenance. However I have been able to log in, just wondering if we should stay out until the all clear?
I wouldn’t rely on consistent access. Our third/pilot environments are both completely down.
2 Likes
Epicor is notorious for extending maintenance windows as the last minute these days. I’d probably wait till it’s officially all clear.
2 Likes
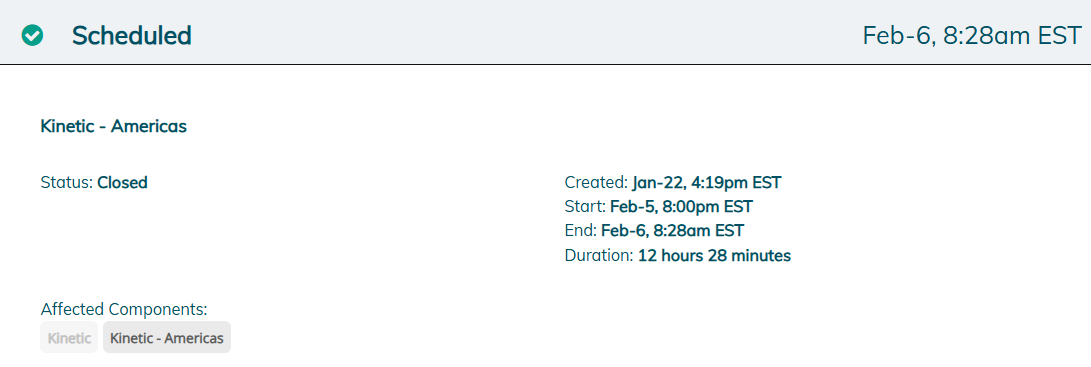
Maintenance window started…email received 8p ET last night.
Maintenance window extended…640a ET.
Maintenance window completed…829a ET.
Tried to log into my Pilot environment at 835a ET…

Happy Friday
2 Likes
Are you referring to the non-production cloud scheduled maintenance? From what I can see, that completed last night at 11:13 pm GMT.

Same, pilot and third both giving 502 and CMP for both says the kinetic version couldn’t be retrieved. Great way to start a Friday
1 Like
UK but the US Pilot maintenance got extended today.
(knocks on wood) our Pilot is up now.
We’re in the same boat.
Working on implementing a go live and this is the second time in recent memory where non-production maintenance was extended into the workday (past 6am) for us and is negatively impacting us.
Only this time we got the all clear and are still getting the 502 Bad Gateway Error.
1 Like
Unfortunately this is normal for Epicor SaaS. It shouldn’t be but it is.
2 Likes
Have you checked the CMP or made a ticket to support? Sounds like someone missed a step in closing out maintenance.
1 Like
I put in a ticket and my pilot and third are now back on 11 minutes later.
2 Likes
I also put in a ticket with support. I haven’t heard anything back from them other than the we got the ticket message.
I am back in our non-production environment though.
Our Pilot’s back up. Two weeks out from a flexed 2025.2 upgrade and testing needs to continue.
1 Like

2 Likes

2 Likes
If you have AMM, verify all tran types print tags in Material Request Queue. Beware of grouped grids.

1 Like
We are a CPQ customer and CPQ updates don’t have a pilot then live approach so you just get the update ![]()
Last week I was hit with a wild issue took me all weekend to fix, sucky weekend. Turned out to be a poorly structured query, but for some reason it worked before the update.
3 Likes
First it was an extended Pilot maintenance…
Now our production instance just dropped…simply opening a menu screen is throwing that wonderfully generic “we apologize, but an unexpected internal problem occurred.”
EDIT 1 - this gets better…opened a ticket at system down status…first reply from support is a link on how to create a support account so they can sign on. We’re down. User Account option doesn’t open. ![]()
5 Likes
We are down as well. (live/production)
1 Like