5 posts were merged into an existing topic: Improve Azure Performance
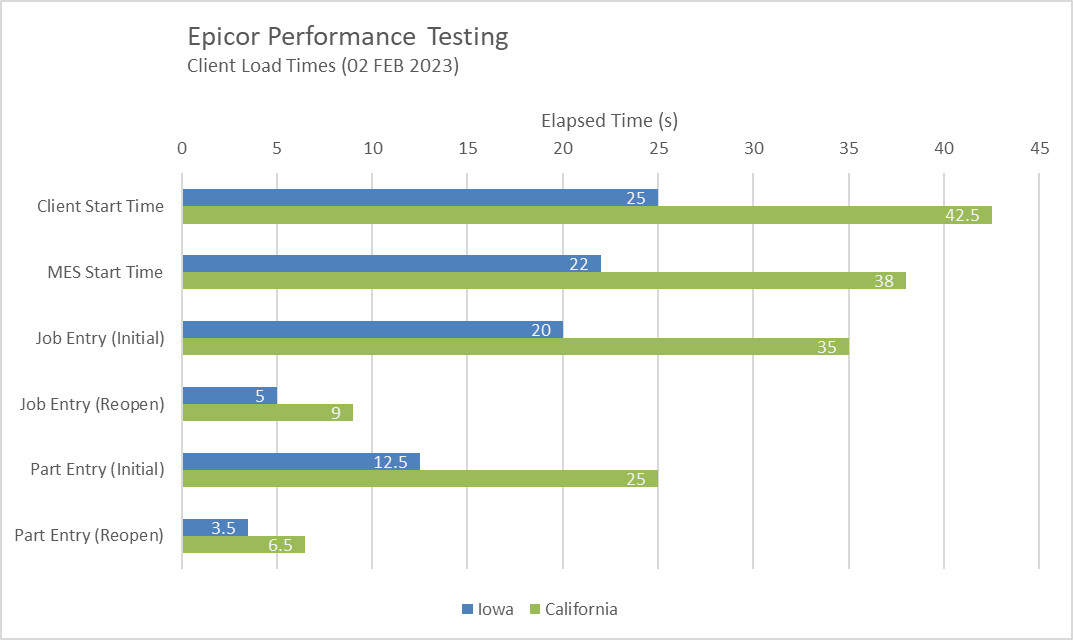
Just to quantify the performance issues I’m referring to… I collected some timings of starting the client, as well as Job Entry and Part Entry forms, both initial open and re-open.
- Epicor Kinetic 2022.2.8
- Windows Authentication
- Active Homepage start screen
How does this compare to you all? Are these load times quite long or is it just us?
To me, this doesn’t seem to align with the Network Diagnostics results and the supposed target values that Epicor states in that tool.
I would say those times do align to a degree with your PDT results. PDT results show that the network time is approx 3-4x Iowa times (and I would ignore the ‘Targets’ mentioned on the screen I don’t think they have been updated since E9 days and think compression went out with E10).
So client load times being 2x longer in California, sounds about right.
I would compare that with the results you are seeing with your Mexico system - the PDT Network should be a pretty similar test vs Kinetic.
Other things you may want to consider: are the forms are caching properly on the local disk, and is RDS the way to go for remote users?
You’re right, the load times are roughly proportional to the Network Diagnostics results.
My problem is, I have nothing to benchmark against. Especially if the numbers in the PDT are old and no longer relevant.
What should our load times be, how do I compare to other Epicor systems? Are these load times abnormally high? They certainly seem that way from the user’s perspective. Waiting 30+ seconds for a form to load is pretty jarring to a user’s workflow.
1 Like
What should your times be? There’s an answer just there - “Waiting 30+ seconds for a form to load is pretty jarring to a user’s workflow.”
Not helpful I realise, but your system can deliver times significantly faster. So what are your options?
Well, as I said, check that the local client cache is being properly used. By default it is c:\ProgramData\Epicor\Server-Port… (or similar). If a user can’t write there, then they have to download the full forms each time, significantly increasing workload and all the wonderful info that @Rich posted about caching won’t help in the least. If you don’t want to give them access to this location, you can specify an ‘AlternateCacheLocation’ in the sysconfig file (Though this does seem to be more of an issue on RDS servers, which brings me on to…)
Consider RDS / Citrix / Other Remote Desktop systems are available: Generally these have much lower bandwidth requirements (they only have to draw the screen), and you are likely to approach “Local speeds”.
Dare I say it, try the Kinetic versions of the screens - I suspect these will be faster.
Work to reduce the reason your network test is 2x as slow over the WAN: Epicor clients don’t have HUGE bandwidth requirements - current differences seem excessive, but it’s been a while since I drew comparative data for sites over a WAN vs LAN. I do however seem to recall a user who only felt the need to go to RDS when they were communicating from OZ to EU.
1 Like
I appreciate the input. Thanks.
Of course. But is it better to keep them as close as possible - i.e. both on one beefy server - or separate them to two servers? Maybe oversimplifying here, but it’s basically a question of whether the lack of resource contention in split servers makes up for the distance you add between SQL and the AppServer, right?
I’ve heard a lot of debate on this but the consensus amongst the community seems to be that split is better. Not only better but so much better that anyone suggesting otherwise should be fired for incompetence. Some people really are that vocal about it, so I decided to listen to them…
We are in Azure and just did an upgrade from 10.2.700 to Kinetic 2022.2. On 10.2 we had one beefy server for SQL and the AppServer, but when we moved to Kinetic we decided to split SQL and AppServer to two machines. We are still throwing a lot of resources at both servers, but performance has definitely decreased. The P&D tool’s SQL Query Speed Test fails on us (it’s 5-6 times slower than the old prod box), and when we look at server logs there are many, many method calls exceeding their millisecond thresholds (we’ve ruled out BPMs as culprits).
Of course, there are a million variables here, but as I rule more and more things out, I am left wondering if splitting servers was the wrong call. I’m optimistic that there is still some sort of misconfiguration we can find and correct, but we’re running out of things to look at. I hate to be the SQL/developer guy who blames his problems on networks and infrastructure, but that’s all I’m coming up with… Any thoughts on this are much appreciated!
Do you know if the VMs were configured with Accelerated Networking? It would make them “closer” and it’s free.
2 Likes
Old thread I know, but in your case I’d spring for RDS (even though I passionately hate RDS)
our MES load time is around 3 seconds
Job Entry 5 seconds
Part 4 seconds
any of these re-opened is Sub second
Thank you. Looks like Accelerated Networking was already enabled.
Turns out servers were on different vnets so Accelerated Networking wasn’t doing anything for us… We’ll be correcting that, also looking into Azure Proximity Groups… I’m optimistic that will make a big difference.
Azure Proximity Groups definitely do make a difference. As for the PDT SQL Test failing, you don’t say which VM sizes you have gone for, but the D Series and E Series VMs pass the SQL Test adequately (when sized appropriately for your user count).
The Millisecond Threshold in the PDT is NOT a target or marker of ‘bad performance’; it is a configurable parameter when you analyse the logs, to allow you to easily pull out ‘long running’ method calls: I would never expect MRP to fail to exceed the threshold.
That said, it is set at 3, because after that users get a little impatient waiting.
2 Likes
Thanks James. I understand the millisecond threshold; it was poor phrasing on my part.
Moving DB and Appserver to the same vNet has made a big difference. Config check passes now and we’re seeing a large reduction in method call durations in the server logs.
Proximity Groups may be our next step.