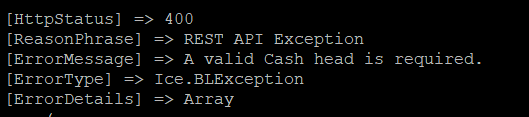
I’m able to create the reverse cash receipt thru this call:
/Erp.BO.ReverseCashReceiptSvc/ReverseCashReceipts
But I cannot get it to actually reverse the cash receipt. As if I hit the Reverse button in Reverse Cash Receipt window.
When I run a GET call on the above call, it says the transaction is posted and to the GL as well. But it’s still in Reverse Cash Receipt and it doesn’t actually process.
Tried the trace log but I don’t see anything that I’m missing.
I tried doing a PATCH call to /Erp.BO.ReverseCashReceiptSvc/ReverseCashReceipts with Posted set to true and GLposted to true. Still nothing.
I see it in epicor, it’s just not reversing the actual transaction.
Just to confirm, have you manually used the Reverse Cash Receipt Entry screen to simulate what you would expect to see? Followed the Trace from start to finish with Write Full Dataset and Write Response Data checked?
After doing some reverse cash receipts manually, I noticed a few things from a cash receipt prior to reverse and after.
Before reverse, the cash receipt would have these values set:
“DepositBalance”: 333,
“DocDepositBalance”: 333,
“ReverseRef”: 0,
“ReverseDate”: null,
And after reversing the transaction I got these values:
“DepositBalance”: 0,
“DocDepositBalance”: 0,
“ReverseRef”: 390664,
“ReverseDate”: “2021-06-16T00:00:00-05:00”,
Everything else in my json is the same, except these. When I duplicate the values and push up a value of 0 for DepositBalance, it does remove the cash receipt from search in Epicor. BUT… it doesn’t change the deposit value in the sales order. So the deposit is still showing on the sales order.
Unsure if there is away and if it’s even a good idea, to manually update the sales order deposit balance. I assumed just like when I post a cash receipt, it automatically updates everything.
Also the ReverseRef, I can’t make heads or tails of. When you process the reverse cash entry you use the HeadNum, example 5050. When I process the reverse entry, It sets the ReverseRef to 5051 (Example). Assumption is, it’s creating a another reference number for the reverse transaction. I can’t add 1 to the HeadNum everytime since one can assume as more cash receipts come in, there will be additional HeadNum’s ahead of the original.
Which leads me to believe… I’m missing something. There has to be a PROC. call that processes and posts the reverse cash receipt entry. Doesn’t show it in the tracelogs but it’s the only thing I can think of that would make this work.
ReverseRef is noted at the bottom of the API documentation as: “Reference to cash receipt which had been reversed.”
Problem with that is that doesn’t make sense. The HeadNum is the cash receipt ID that is used to reverse.
Example:
If I reverse cash receipt 1000, my HeadNum is 1000. But when I process the transaction, ReverseRef would be 1001. If anything ReverseRef is the ID to this transaction, the actual refund transaction. Unsure what is creating this ID.
When the cash receipt is created it sets a head number. Lets say I create one and it creates a HeadNum of 1000.
When I go to reverse the transaction in Epicor, it creates a new HeadNum and links the two. For example, after I reverse the transaction the HeadNum would be 1001
So my initial cash deposit HeadNum is 1000
My reversed cash deposit HeadNum is 1001
Alright, pretty straight forward. Here is somethings I’m trying to figure out.
-The headnum for the reverse transaction. I thought about selecting the last HeadNum through a GET call to /Erp.BO.ReverseCashReceiptSvc/ReverseCashReceipts and adding 1 to that number. And then send a POST call to the same endpoint with my new headnum and the additional information to create the reverse transaction. When I do it though, epicor gets the data, and I can see it when I do a GET call but it doesn’t seem to actually complete the transaction. The even odder thing is, say I create a reverse transaction with a headnum of 1001, then I go into epicor and try to refund the original transaction, it will still allow me and will then create a second headnum of 1001 for the reverse transaction. Meaning, there ends up being two 1001 headnum transactions.
-Another werid thing. When I try posting with my groupid that I posted the original transaction, it comes back with an error saying, “Group references invalid value.” But if I remove that from the POST call, it creates it and has the groupid as blank. I tried many different group id’s but nothing worked.
This is why I recommend doing all the business object work in a function. Using REST + OData is two abstractions away and can lead to “weird things.” Still have to use the trace but there are fewer moving parts. That’s just my humble opinion.
It keeps business logic out of your client. It’s very similar to BPMs, so if you’re comfortable there, you’ll be right at home. There are a few posts here about them and the documentation gets you the basics. The function then becomes available to any client: web, Blazor, Teams, etc.
Thanks again Mark! I appreciate all your help here.
I wasn’t binding my variables and that was the cause. I missed that part in the posts I was reading on here some how.
Seems the function method is really powerful. A little more work to get going. I can see why you say there shouldn’t be much trail and error. If using functions, it’s pretty straight forward. Using the standard REST calls there seems to be a level of disconnect. The call should do X but it doesn’t completely do X. Where as making a function call, you can duplicate exactly what the trace log says and go.
Regardless, this will work and get our automation on track.