Well… I apologize in advanced for the string of curse words that follows…
JESUS 48 HOURS OF HELL FOR SOMETHING SOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO STUPID…
For the future poor bastard here’s what the issue was. And it was in fact the EXACT same issue that Josh had… F******************************************CK!
Note on my first post I alluded to having populated the AppServerURL here in Live a cuple of days ago

The other thing we do quite often is clone Live into other environments for Development and Training purposes. So about… 48 hours ago, we cloned live into the train Db. I believe that’s enough for you to go… ohhhhhh shit…
But for those who want more… when we cloned the DB that field carried through which means that now Epicor Train was sending all its “Tasks” to the Live_DocStar AppServer (for production)
The way that Epicor works is it looks at the pending tasks , picks the first one, marks it as “TAKEN” and starts working on it. The problem is that when the Training App Server took that one Task and “marked it as taken” it was doing so with the Live AppServer which promptly said… I don’t know what the hell that task is… and shrugged its shoulders. In the next loop, the same task was already there and so the app server dutifully sent the task for processing… ad-infinitum.
Over 48 hours Tasks Accumulated in Train (a lot of Multi Company Processes run every 5 seconds) and well you can see what can happen, there are thousands of Tasks in the Immediate Run Request in Train that were constantly being “picked up” by the Live App Server but never told whether the task completed or failed. So it tried and tried again.
Current Status
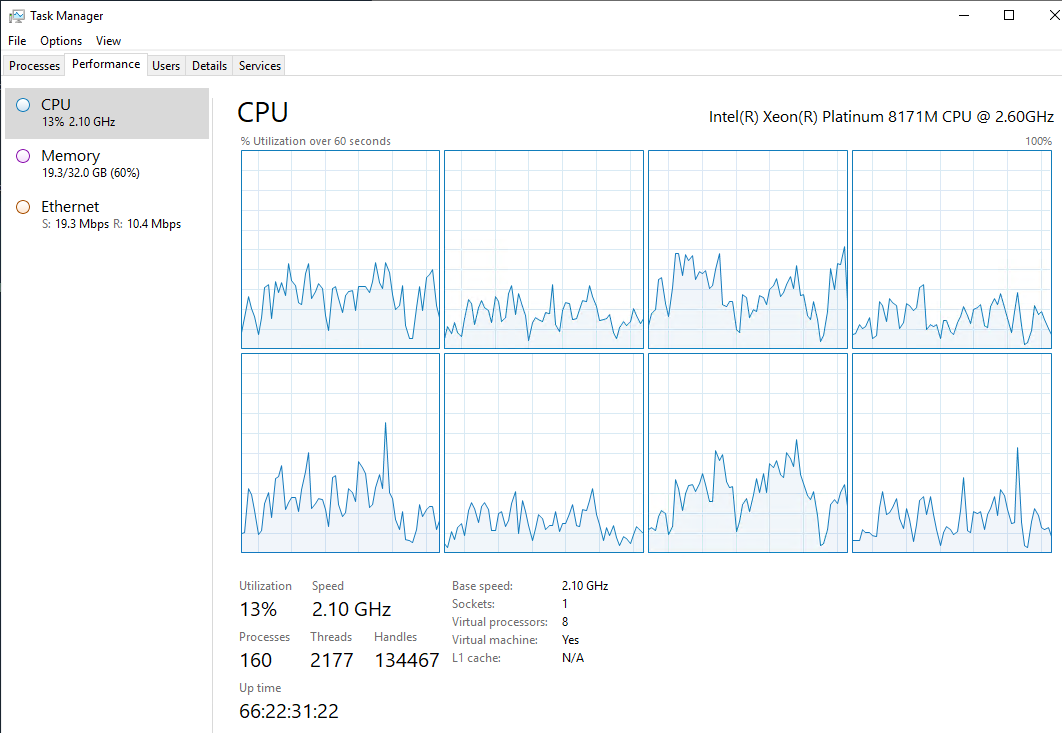
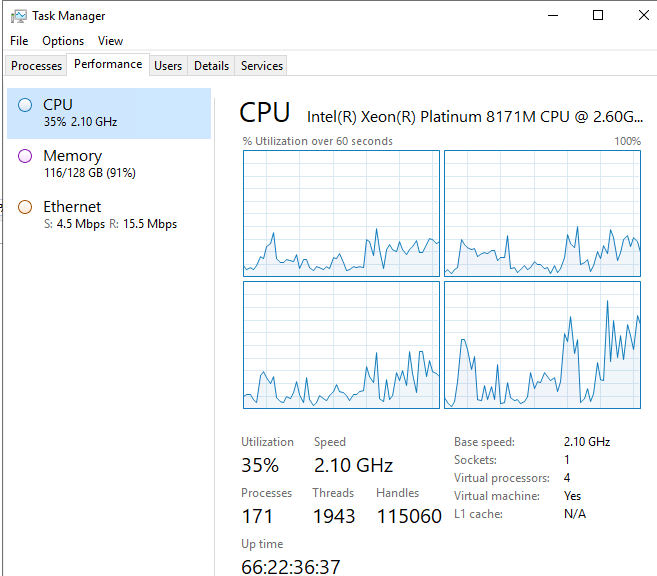

Thank you sooooooooooo much @Jonathan @hkeric.wci @jgiese.wci @Banderson @hmwillett @Chris_Conn the entire community of Brent Ozar over in slack, special mention to [alevyinroc] who called out the 10K batches per second load during some troubleshooting yesterday… which eventually lit the bulb that lead to this solution and my poor poor users…
on to fight another day…
@Epicor… for the love of God verify that the Db’s are the same when the Appserver sends tasks to the Task Agent… Save a life… ![]()
Further more that query it kept running over and over again was specific to Multi Company Processing.
CC: @JeffLeBert please buddy do a HMAC verification or something to let the AppServer know the request came from the “right” Db anything… anything bud! Save the next guy