10.2.500.27
So 2 days ago we populated this field

In System Agent because we were trying to run some reports via REST and it required that field. Soon after and unbeknownst to us performance in the system Tanked and has been tanked for 48 hours.
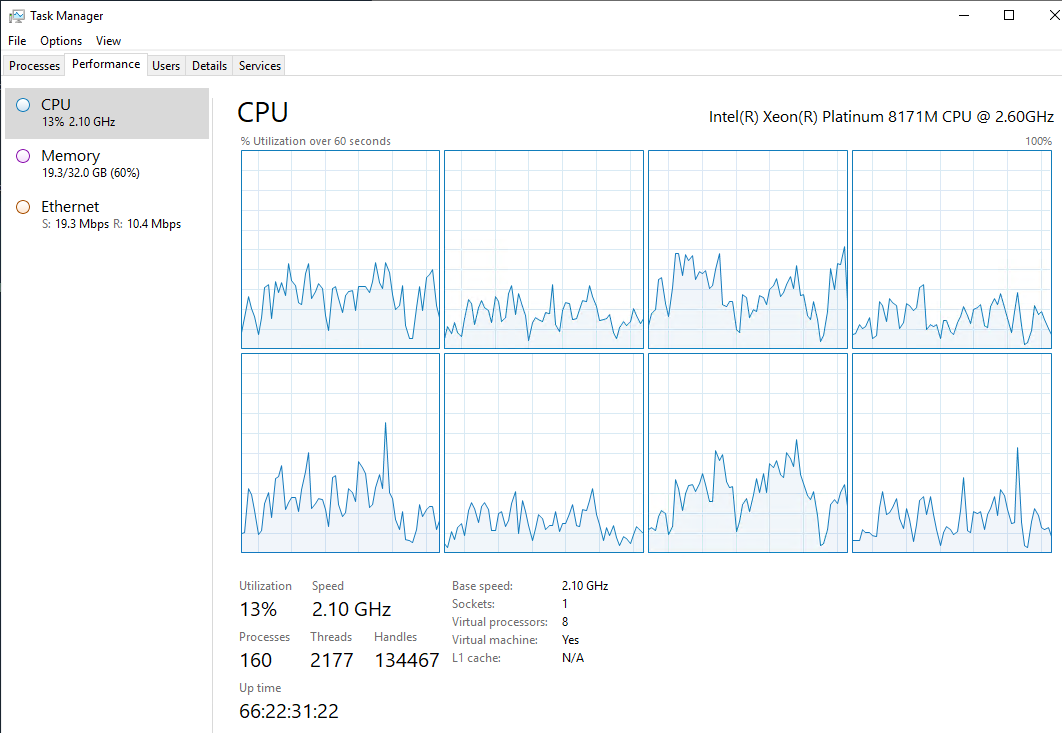
SQL Server is Pegged at 100% and I haven’t been able to find which “bad query” is causing the issue.
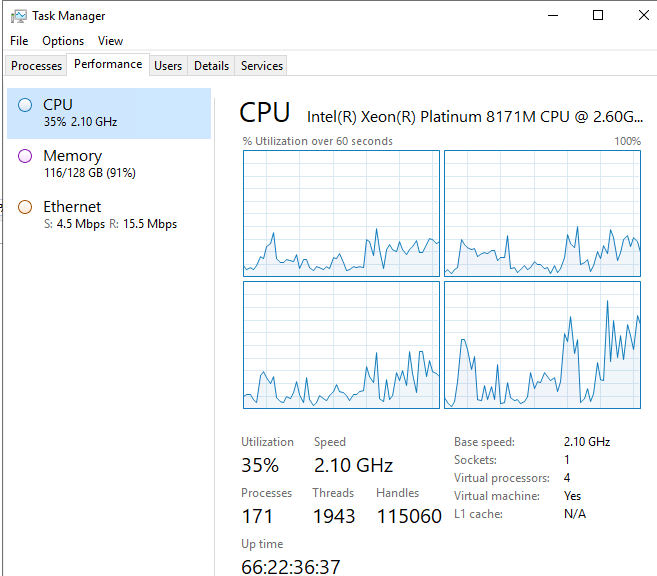
After much testing and prodding I realized that app01 (the server which hosts our System Agent Task Service / and Printing App Server) was also pegged
I soon realized that turning off that App server also relieves the issue in SQL. We are throughputting 300Mbps of traffic from App01 to SQL
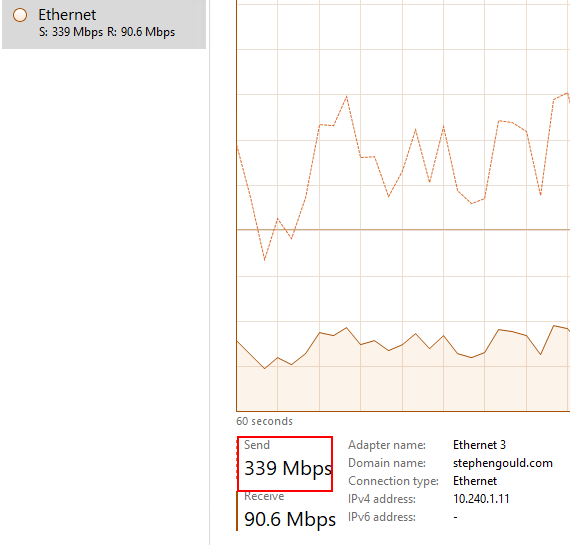
After much testing and messing I used profiler to determine that the App server is just running wild with queries to the TaskParam table.
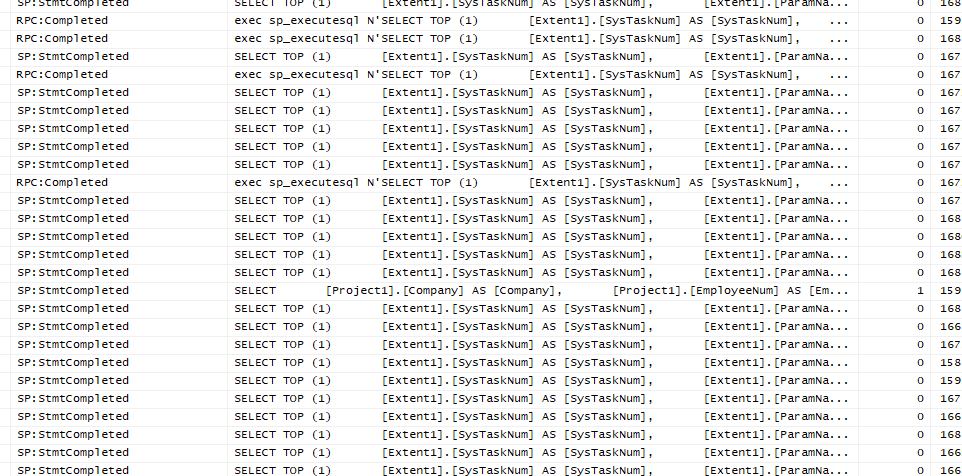

SELECT TOP (1)
[Extent1].[SysTaskNum] AS [SysTaskNum],
[Extent1].[ParamName] AS [ParamName],
[Extent1].[ParamLabel] AS [ParamLabel],
[Extent1].[ParamType] AS [ParamType],
[Extent1].[ParamDataType] AS [ParamDataType],
[Extent1].[ParamCharacter] AS [ParamCharacter],
[Extent1].[ParamDate] AS [ParamDate],
[Extent1].[ParamLogical] AS [ParamLogical],
[Extent1].[ParamInteger] AS [ParamInteger],
[Extent1].[ParamDecimal] AS [ParamDecimal],
[Extent1].[ParamToken] AS [ParamToken],
[Extent1].[SysRevID] AS [SysRevID],
[Extent1].[SysRowID] AS [SysRowID],
[Extent1].[ParamLong] AS [ParamLong]
FROM [Ice].[SysTaskParam] AS [Extent1]
WHERE ([Extent1].[SysTaskNum] = @p__linq__0) AND ([Extent1].[ParamName] = @p__linq__1) AND ([Extent1].[ParamCharacter] IN (@p__linq__2,@p__linq__3))
Over and over again up 10K times a minute, we have recycled, the app server and even spun up a completely separate System Agent elsewhere and turned / killed this one off.
But this appserver specifically continues to do this, we can’t seem to stop it even with turning it off compeltely as soon as we turn it back on it goes insane again.
We don’t want to detroy it (delete it) because other apps rely on it. We already removed the appserver URL form System Agent Maintenance but that didn’t seem to help.
Note this app server is NO LONGER BEING USED for ANYTHING other than for some “REST” calls from the Hand Held. Yet it continues to hammer SQL at 10K queries a minute all the same.
HELP!!!