I am attempting to run a handful of BAQ exports to pull out a snapshot of our important tables. I have the following batch code. I expect it to export each table into one file. After I started the process I realized I had left my filetype as CSV. So I wanted to stop the process and change they type to XLS.
The only way I could figure out how to do that is with the windows task manager. Looking at my destination folder, it looked like all the files were in there and complete. But they were all slowly increasing in size. I deleted the files while the process was still running and it kept creating new files until I finally got into task manager and killed the DMT processes.
Is this the best way to setup this batch file?
Is there any other way to stop a process that was started via batch file?
Is there any way to know how long the processes will run?
@NateS I have to ask a potentially obvious question - why go external?
You could create a second SQL database (we have one called ‘Utility’) and do SQL to truncate and fill those tables as the snapshot, or not truncate and datetime stamp each row to collect snapshots. And then use Excel’s data options to view the data in those tables…
But to really answer your question - you might be able to start a DMT “playlist” rather than individual jobs.
As for stopping - you did the right thing. Task Manager is how it’s done. And there really is no way to know how long it is going to run for until you’ve run it a few times and check file datetime stamps against when you started it. You could add a few ‘logging’ statements to the batch file and redirect it’s output to the log file to get some good run duration data.
I thought this would be a simple way to just get a snapshot of our data before I go into live and use DMT to update all of our parts and jobs. This is working, its just a bit slower than I expected. There is a lot of data to get through and it all comes down through the cloud, so i guess it just has to take a while.
I have never setup a local SQL DB. I wouldn’t know where to begin with that. I think this exported data will be enough for now.
This looks like an OK thing to do to me. I have a similar ps file that occasionally does a bunch of DMT exports of queries before it does a bunch of imports. With larger datasets, it definitely takes longer to process. I don’t know of any way to evaluate how long it’ll take except perhaps do one manually and see how long it takes then expect similar results during your automated run. I also was a bit worried about whether it closed things up nicely… and how to tell whether it was working. It’s been running here and there a few months now and I haven’t had to take down extra sessions or anything like that, so it seems ok so far. You could turn on the UI in your run and see if watching it would provide confidence of “working as expected”.
no worries - I made an assumption you could do another DB, but since you are in the cloud, that won’t work - sorry!! I’m on-prem and keep forgetting to clarify my answers - or check the author’s status before I reply…
But yes - a lot of data form the cloud will take a while of course, and DMT is using the same facility as the client so it’s really only minimally faster that running the BAQ in the client.
However, since you mentioned that the batch file spawned multiple DMT processes, perhaps it was consuming too much bandwidth. The DMT Playlist method might only spawn a single DMT process thus limiting the bandwidth and improving speed, but it will run things linearly so the overall time might be longer. I’ve not done the playlist method so I just guessing at this point.
and then there is the idea of using Excel’s ODATA capability and accessing the BAQ service directly via Rest… so may ways to get this done
It turns out that the DMT batch export will only export in CSV format. When I open these CSV files the comment field is throwing the rows off. Line feeds/carriage returns inside the comments are translated into new rows in the CSV file. Is there a standard way to export data so that I don’t lose my leading zeros, and avoid the extra line feeds in the comments?
in your BAQ you’ll need some calculated fields to handle all that.
Leading zeros can be tricky - does it have leading zeros in teh CSV, but not when you open it in excel? that is a common issue with Excel - you’ll need to read up on how to ‘import’ a CSV file and set the column formatting to Text. If the CSV is missing the leading zeros, then in the BAQ you’ll need to read the value like text - like cast(key1 as nvarchar(10)) in a calc field will/should keep the Key1 ‘string’ as a string.
As for the comment field - maybe a small string function that strips out CR/LF and some other special characters. You can handle that with the REPLACE() function too - something like
I have those calculated field in place for my other exports. I was really hoping to avoid adding calculated fields to these exports.
The exports do have leaving zeros, so I am hopeful that I can get them to pull into Excel eventually.
I will play around with importing the CSV in various ways to see if I can get it to work. Since I am exporting every field in these tables, I don’t want to have to create tons of calculated fields to cover each one that could possibly be mistranslated in the CSV.
I don’t know why yours is failing on having a line feed, mine has it on export to csv per below. Weird. Is it your first row of data that has the characteristic of line feed/starting with zero, etc by any chance? I have found Excel helping when the first row of data looks to be a number, etc., vs when not.
Some of my part numbers end in E105, E110, etc, with numerical chars preceding. Excel likes to make these scientific notation numbers. I have worked around by not opening and changing the csv. When I do that, it imports ok, but gets screwed up if I open the file and save. However, that won’t help you too much with working over the data. I have found formatting the column as text and then pasting my E110 part numbers in stops the scientific notation formatting, but that’s not an export, so I’m not sure this is helpful.
Sooooo, since you’re already in the cloud, have you thought about a more cloudy solution to this problem? Pulling data down is so, well, uh, on-prem thinking.
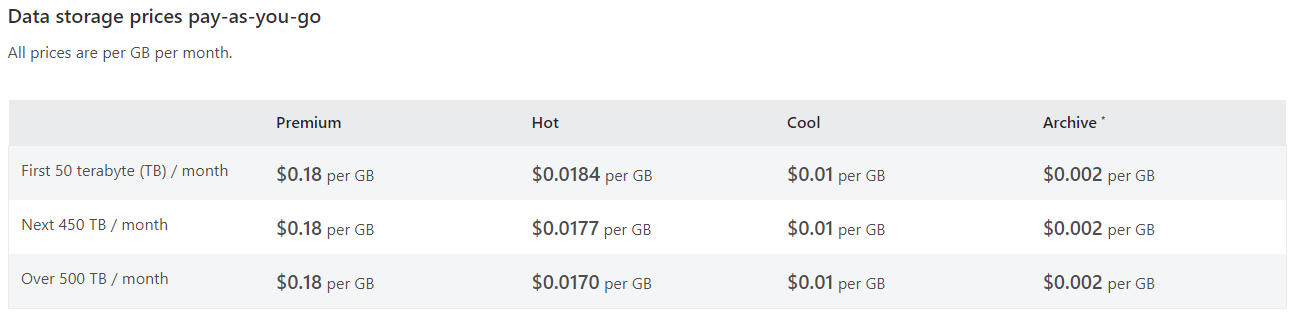
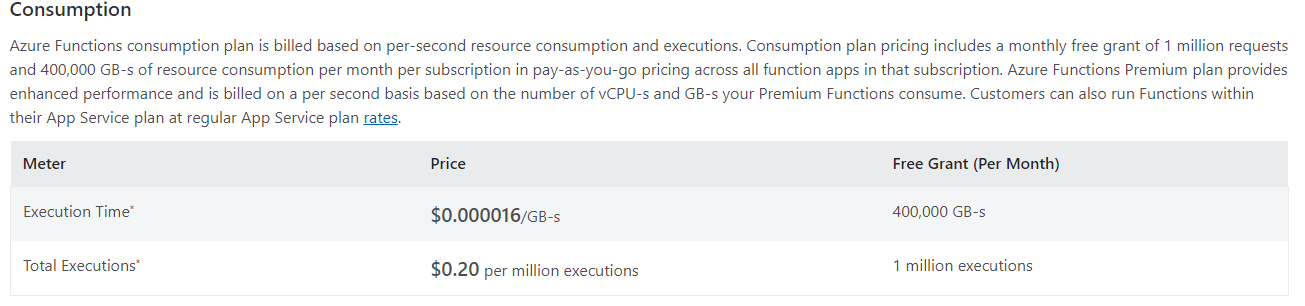
With an Azure Function (which can be run on a schedule), you can call the BAQService and download the files to inexpensive Azure Blob storage. In Blob storage, your data will be protected from any malware that might hit your local network. You can add rules to auto-delete the files after a period of time, and you can even make it immutable for further protection.
The Azure Function can be written in PowerShell, which means you have full control of the data format: CSV, TSV, JSON, etc.
And if you host the function/storage in the Azure Central Region, it will be wicked fast since it’s staying on the regional Azure network backbone.
Finally, the cost would be far cheaper than the system you’re currently using to store the files on.
The terminology just keeps getting better and better. “Blob” storage?! Sounds better than cloud! I need to learn more about this. I am just keeping these copies of our tables as a sanity check. If something terrible happens, at least I have these tables to reference.
Can you point me to some epicor resources related to this whole idea?
Just so I understand, the blob storage thing is a third-party service we would purchase to hold this data. And this has nothing to do with Epicor, other than that is where the data source is.
Right?
This seems nice, but it also seems like a lot of overhead for a temporary file storage. How is this cheaper? I can see how it would be faster, but right now my storage is free. If I use this service I have to pay a monthly storage fee.
Correct. This is an Azure service. Amazon has a similar service called S3. The PowerShell that runs on a timer in the cloud is a different service called Azure Functions.
It is not free, it is covered by other current assets that are paid for, but that’s not free. You still have to maintain the devices, electricity, security, operating systems, and back up that data. To match the capability of blob storage, you would also have to keep a copy of the data at another facility 100+ miles away. You would have to write a script to delete old files and I’m not sure how you would make immutable copies without buying more hardware.
I finally tried pulling data into Excel using OData and REST. This process seems super clunky and slow. Normally I can only get 100 records. If I set the top N records, trying 10,000 records, it seems to run forever and never spits out any data. So far I have only been able to take small bits of data out. If I tried to use this to export all the fields in the tables I want, I expect it would never load.
Am I missing something big in using OData/REST in Excel?
No. You’re still downloading all of those records over the WAN and adding the overhead of Excel parsing each record into cells. Are you using the BAQSvc or individual BOs?