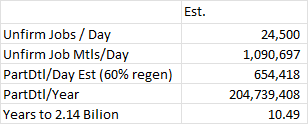I’ll try to keep this brief - this weekend, MRP stopped working. I looked into it, and discovered that I couldn’t even create/save a job, and the root cause was a SQL DB error:
Arithmetic overflow error converting IDENTITY to data type int
And the SQL query that was throwing this was an INSERT statement trying to create a row in the Erp.PartDtl table. Apparently this has an IDENTITY (auto-incrementing) integer column called PartDtlSeq and since we churn a lot every night in our MRP runs, we managed to hit the ~2.14 Billion limit of integers. I also observed there is so much churn in this table (we only have about 1.1 Million rows in there currently) that the smallest PartDtlSeq currently for us (other than a few anomalies I can probably just delete) was at about ~1.6 or 1.7 Billion.
So I got our Epicor, MRP, Job Creation, Order Creation, PO creation (anything that would insert a PartDtl record, i.e. affect Time Phased Inquiry) back up and running by resetting the PartDtlSeq IDENTITY back to 1:
DBCC CHECKIDENT('Erp.PartDtl',RESEED,1)
But this leaves me with questions:
Is this a design problem or bug? Should I report it?
Did I just introduce some other issue we haven’t stumbled upon yet, but is going to bite us soon?
Could I have changed the column type to BIGINT and been okay, or would that have just broken application server layer of Epicor?
Surely others would have run into this before us, right? I mean, we’re pretty small company (although maybe it’s something to do with our BOM structures, or how we run MRP so heavy every night and re-create some 12k jobs?)
I pay for support, I’ll file a ticket a the drop of a hat, or even the mere desire to drop a hat. Let them figure out the design vs bug question. In fact, I’d have hit them up before running any SQL commands.
Having said that, you’re probably fine. PartDtl isn’t upstream of much, if anything, and the system itself will basically nuke the whole table when MRP runs a clean sweep.
FYI: We regenerate one to two thousand unfirm jobs per night. It’s been six years since we reimplemented our ERP on E10. Our PartDtlSeq is at ~25 million.
To get to 2.4 billion with ~12,000 jobs per run you would have had to run MRP 200,000 times. Even if you ran a full regen every day of the week that would take 547 years. I would also have gone to support before doing anything.
In theory going to support first sounds good, but it was late Sunday evening and we were basically in a near complete down state, since you cannot create a job, an order line, a PO line, etc. while PartDtl table is broken.
I guess I’ll create a ticket now so they can at least let me know what they think, thanks for chiming in.
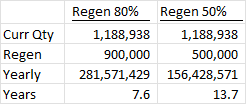
As far as the numbers go, I calculated it a different way. I’m looking at how many records we have in there now, and estimating (very conservatively I feel) that somewhere between 50% and 80% of the records are destroyed and re-created with our nightly MRP runs, which run 6/7 nights of the week every week, and getting between 7.6 or 13.7 years before we run out of PartDtlSeq… it took us about 10 years the first time, so that seems plausible.
We’re almost at 1 billion. Should cross it by the end of next week.
So, for us MRP used to process 3.5 million unfirm JobMtl lines once a week. Now it does 600-700k, 5 days a week, after I changed some settings (like Days of Supply past X days). Either way it’s about the same churn through numbers, 3-4 million per week. [EDIT: I thought that was off. We do 1.1 million per night now, so 5-6 million/week.)
But while it took us 6.5 years to get to 1 billion, I think we could hit 2 billion by the end of 2024. Eek.
[EDIT 2: Oy, I am striking out left and right. 5.5 million/week = about 200 weeks for us to hit 2.14 billion, i.e. 2027. OK, I am less panicked now. ]
No, it doesn’t touch any existing records in the table. It only resets the next added record to have a PartDtlSeq of 1. For us, that was no problem, because our smallest PartDtlSeq is up at like 1.6 Billion and some change.
I’m not 100% certain it didn’t screw with something yet but I do no Time Phase uses the DueDate on the records for sorting for us. And we’re going on 3 days now and nothing has jumped out at anyone yet.
We have about 24,500 jobs created every night by a full regen run, and about 1.1 Million job materials for those jobs. So you can see from the chart here, this seems to be reasonable that we’d run out in about 10 years (the only number I “tweaked” was the one in the middle, estimating about 60% PartDtl records are regenerated nightly… .that might be really low though)
Here are some SQL queries I use to investigate this stuff, might help:
-- Some summary statistics about PartDtl table
DECLARE @identCurrent INT = IDENT_CURRENT('Erp.PartDtl');
SELECT COUNT(*) AS Qty, Min_PartDtlSeq = MIN(pd.PartDtlSeq), Max_PartDtlSeq = MAX(pd.PartDtlSeq),
IdentCurrent = @identCurrent,
NextCollision = COALESCE(
( SELECT MIN(pd2.PartDtlSeq) FROM erp.PartDtl pd2 WHERE pd2.PartDtlSeq > @identCurrent),
2147252874)
FROM Erp.PartDtl pd
-- Summary statistics about most recent MRP run
SELECT MRPToday = (SELECT COUNT(*) FROM Erp.PartPlant
WHERE ProcessMRP = 1
AND ((MRPLastRunDate = DATEADD(DAY, -1, CAST(GETDATE() AS DATE))
AND (MRPLastRunTime / 3600.0) > 18.0)
OR (MRPLastRunDate = CAST(GETDATE() AS DATE)))),
MRPTotal = (SELECT COUNT(*) FROM Erp.PartPlant
WHERE ProcessMRP = 1),
RecalcNeeded = (SELECT COUNT(*) FROM Erp.PartPlant
WHERE MRPRecalcNeeded = 1 AND ProcessMRP = 1),
PartRunMRP = (SELECT COUNT(*) FROM Erp.PartPlant WHERE PartRunMRP = 1 AND ProcessMRP = 1),
UnfirmJobs = (SELECT COUNT(*) FROM Erp.JobHead jh WHERE jh.JobFirm = 0 AND jh.JobClosed = 0),
UnfirmMtls = (SELECT COUNT(*) FROM Erp.JobMtl jm
JOIN Erp.JobHead jh ON jm.Company = jh.Company AND jm.JobNum = jh.JobNum
AND jh.JobFirm = 0 AND jh.JobClosed = 0)
Sure, but in the case of a tie, well, I don’t know what Epicor uses, but in my own versions of Time Phase, I have to use PartDtlSeq as the tie-breaker sort, in order to get the same sequence that they have.
But in the end I guess it would all shake out the same. Ties are ties; none are genuinely “first.” As long as the sorting is the same, no one should ever know.
And man, by all means, you did what was necessary. Still amazed at this.
For those talking about HUGE number of jobs created (over 10k per day), I am wondering how many of you are using this feature in MRP.
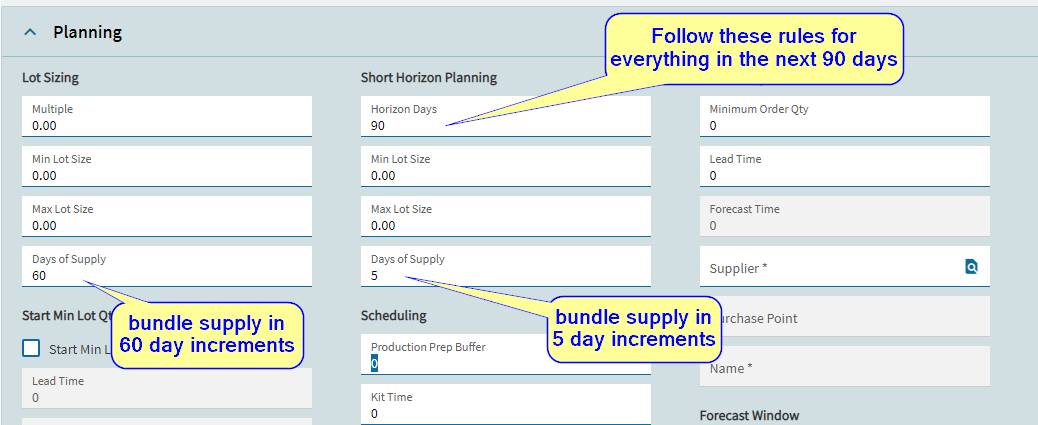
you can set a SHORT HORIZON planning days… everything within this number of days is planned using the short horizon rules
anything OUTSIDE the short horizon can follow different rules.
In the example below, I am saying that for the short horizon of 90 days (3 months) we actually want to have our jobs bundled into 5 days of supply groupings… (but this could be changed to 1 for one job per day)
in the regular days of supply, i have set Days of supply to 60… what that means is that even if i have one demand per day for a year, i would only get one unfirm job per two month period. This can substantially reduce the clutter of future jobs that will not be released for a long time. This also results in MRP taking less time to generate those jobs.
We do! You suggested it. It’s been really helpful.
But ironically it results in making this problem worse. Because we went from 3.5 million rows once a week to 1.1 million rows every day, now that MRP is lean enough to run nightly.
Thanks for that @timshuwy! Started an internal conversation with our main scheduler and purchaser to look into using this. For us, it might be we use short horizon on min/max lot size, because our main churn is caused by our finished goods we use 1 qty per job, even though we might produce 70 of the same part on the same day, it’s 70 jobs, not 1 job for 70.
Is there any documentation anywhere on the new Planning BOM feature that was supposedly added to Epicor recently? (We’re on 10.2.400, but going live on 2022.2 upgrade in a few weeks) I’m wondering if that might be an even cleaner solution for us, but I haven’t been able to find any documentation or videos on it. Honestly, I can’t seem to find that video library site Epicor was running with there for awhile, maybe it got shutdown?
For anyone that stumbles on this or is potentially interested (@JasonMcD ), after a bit more back and forth with Epicor support and reproducing the issue in our pilot environment, they dug a little deeper and found a problem / development task related to this:
The reported scenario has been reported already to our Development team and will be addressed under bug number ERPS-163732 in a future version.
Please follow Problem number PRB0235639 for further updates on the EpicCare portal under the “My Problems” section.
They also provided a datafix program that is supposed to re-sequence the table and resolve the issue: ( CRUPartDtlSeq_2022_2_12_SQL.zip ) that you can probably ask for if you’re getting close or have run into this issue.
Oh boy, that’s a fun thing that many long term MS-SQL DBA-aligned persons have been discovering the hard way for ages! IDENTITY always returns a unique (to its table) int. It always returns a number that’s incrementally consistent with its configured direction. It always returns an int that is not incrementally closer than the minimum increment value it was configured with. Microsoft never technically promised you the exact next incremental value. SQL Server sometimes plays safe and skips by an order of magnitude or three.
Specific to Epicor: If you’re a SaaS customer, you may not be the only one who has ever caused IDENTITY to increment.