Scheduling blocks seems like a simple feature at first glance but multiples layers of complexity are hidden under the surface. The documentation is severly lacking and a lot of people are asking questions on this forum. So, here is the summary of all the tests we did over the years.
English is not my first language, sorry in advance for typos
Configuration - Resource Group
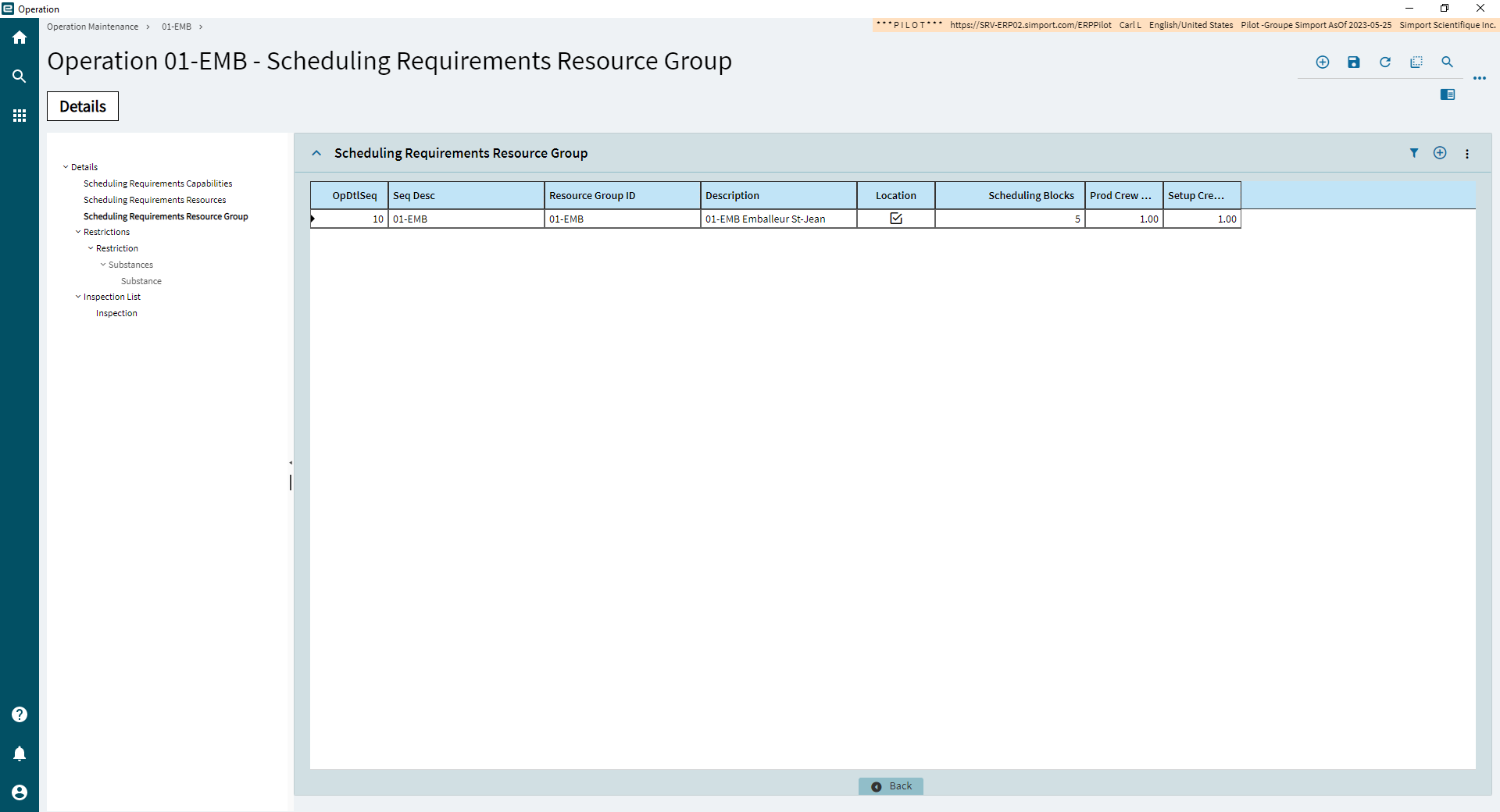
To enable the use of scheduling blocks, the “Split Operations” check box must be checked. This instructs the scheduling engine that operations assigned to this resource group can be divided evenly between multiple scheduling blocks.
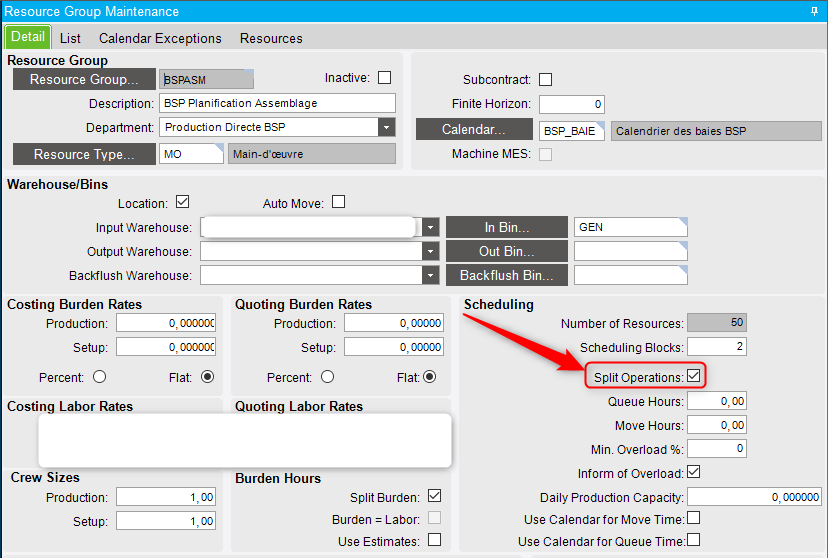
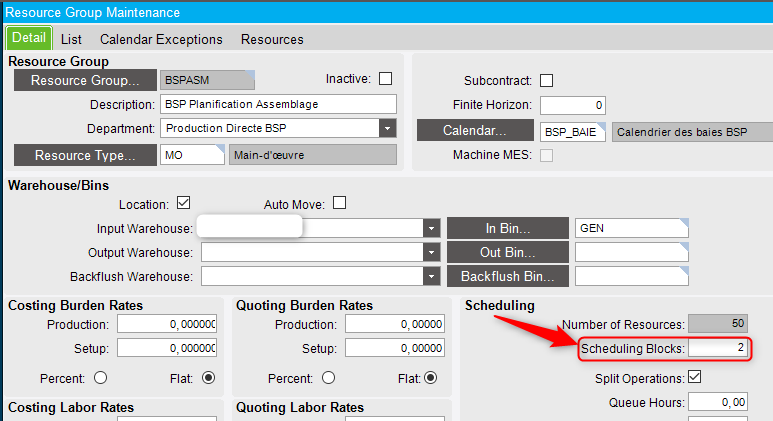
There is also the possibility to assign the number of scheduling blocks at the resource group level. However, this value doesn’t have any impact on the scheduling engine ; it only defaults the scheduling blocks value when an operation is added to a job, having this resource as primary scheduling requirement configured in operation maintenance.
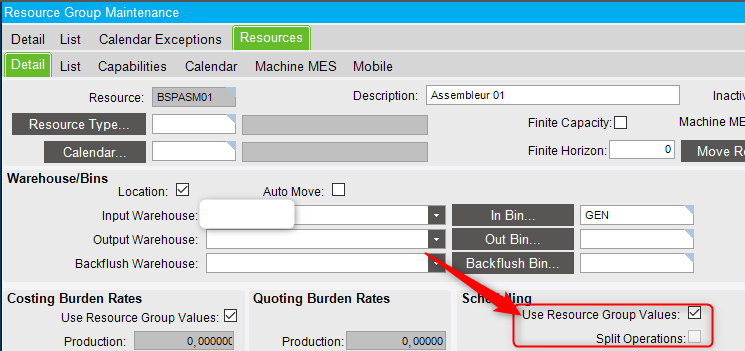
It is possible to set the “Split operations” only on specific resources within the resource group. If so, you’ll have to uncheck “Use resource group values” and use the “Split operations” checkbox at the resource level.
Configuration - Job Operation
In the job operation, first make sur that a resource or resource group with “Split operations” enabled is assigned. Then, assign the number of scheduling blocks desired in the corresponding field
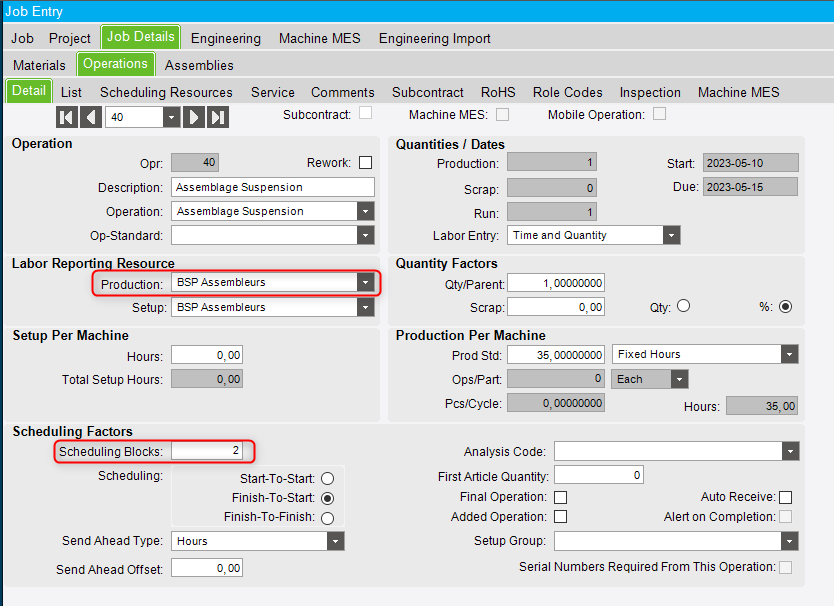
Theorical Behavior
As per the field help : “The Scheduling program will divide the production time by the number of scheduling blocks. This program then finds resources that have capacity available in the required time frame”
For example, if an operation with a Prod Standard of 30 hours has 1 scheduling block, the operation is scheduled as one single block of 30 hours. If the operation has 2 scheduling blocks, the operation is scheduled as two distinct blocks of 15 hours, and so on :
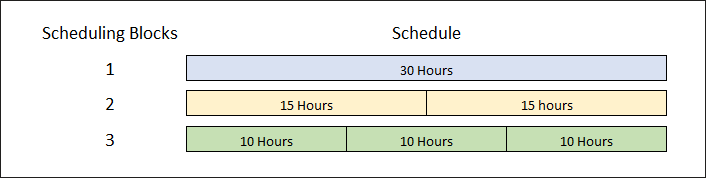
Now, each block can be assigned to a different ressource, which can reduce the lead time of the operation.
For example, here is the previous 30 hours operation with 2 scheduling blocks. Both scheduling blocks are assigned to the same resource, one after the other :

The resource works on the first block for 15 hours, then on the second for 15 hours, for a total actual man hours of 30 hours and a lead time of 30 hours.
Now, this time, the scheduling blocks are assigned to different ressources :

In this last example, both resources works at the same time on the same operation for 15 hours. The total actual man hours is still 30 hours but the lead time is reduced to 15 hours.
So, in theory, scheduling blocks can be used to specify how many “people” are working at the same time on an operation to reduce the lead time.
The reality is a little bit more complex, and the behavior is widly different between finite and infinite scheduling.
Real Behavior - Finite Scheduling : situation #1 - (Operation assigned to a resource group)
For this first situation, we’ll work with job #000973. The operation is assigned to a resource group :
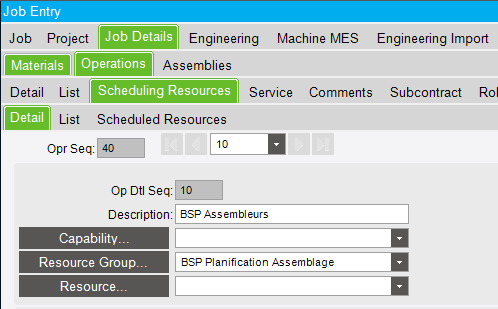
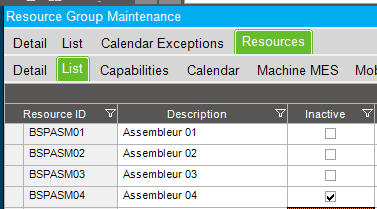
This means that we let the scheduling engine selects the first available resource in this resource group to work on our operation. Now let’s say that this resource group only has 2 active (available) resources :
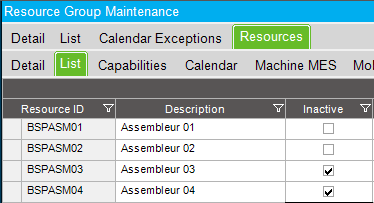
Now we remember that our operation has a prod standard of 30 hours and 2 scheduling blocks :

What happens if we lauch global shceduling in finite mode ? Something like this can happen :
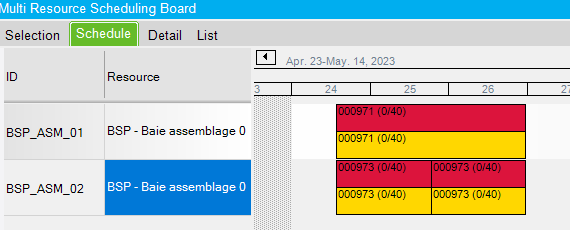
In this situation, another job 000971 had a higher scheduling order, so it was scheduled first. It was assigned to the same resource group than our job 000973, so the first available resource (BSP_AMS_01) was assigned to its operation.
Then, job 000973 was scheduled. The operation is divided in two 15 hours scheduling blocks. The engine find that ressource BSP_ASM_01 is not available so it schedules the first 15 hours block to resource BSP_ASM_02. After that, the engine tries to schedule the second block. Since BSP_ASM_01 is still not available, it schedules the second block right after the other, on resource BSP_ASM_02. The operation lead time is 30 hours even if we set 2 scheduling blocks.
Real Behavior - Finite Scheduling : situation #2 - (Operation assigned to a resource group)
Here is another scenario. Job #402200. The operation is assigned to a resource group :
The resource group has 2 active resources :
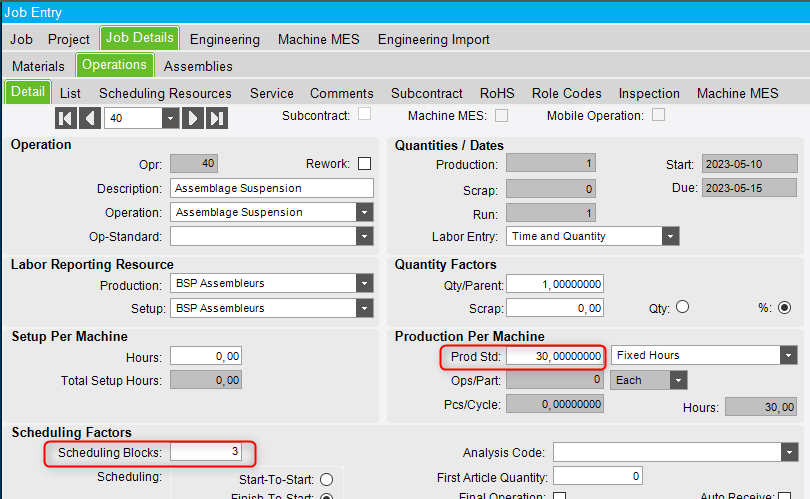
The operation has a prod standard of 30 hours and 3 scheduling blocks :
Let’s run global shceduling in finite mode. Something like this can happen :
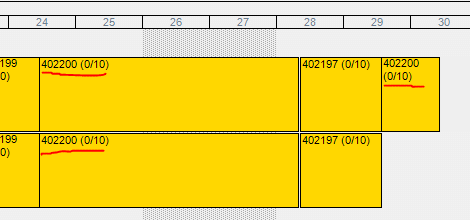
In this situation, another job 402197 had a higher scheduling order, so it was scheduled first. It was assigned to the same resource group than our job 402200 and had two scheduling blocks. Since both resources were available, both scheduling blocks were assigned at the same time to both resources.
Then, our job 402200 was scheduled. The operation is divided in three 10 hours scheduling blocks. On the 24th, the engine finds that both ressources are available and that the scheduling blocks can fit before job 402197 starts, so the blocks are assigned. The third and final block now wait for any resource to be available, which happens only when job 402197 is done. So, the final block is assigned after job 402197 is done.
The total man hours for our operation is still 30 hours but the lead time is nowhere near the theorical 10 hours.
Real Behavior - Finite Scheduling : situation #3 - (Operation assigned to a resource group)
Job #404040. The operation is assigned to a resource group :
The resource group has 3 active resources :
The operation has a prod standard of 30 hours and 3 scheduling blocks :
Run global shceduling in finite mode. Something like this can happen :
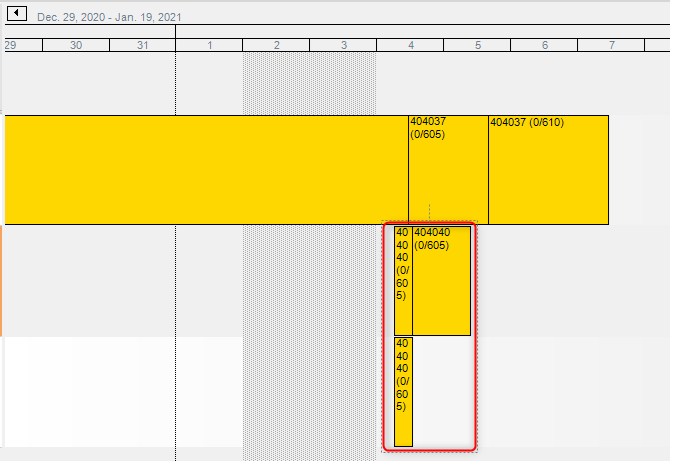
In this situation, other jobs had a higher scheduling order, so they were scheduled first on resource #1.
Then, our job 404040 was scheduled. The operation is divided in three 10 hours scheduling blocks. On the 4th, the engine finds 2 out of 3 ressources are available, so two blocks are assigned. The third and final block now wait for any resource to be available, which happens only when our first two blocks are done. So, the final block is assigned after blocks #1 and #2 are done.
The total man hours for our operation is still 30 hours, but the lead time is 20 hours. This also mean that 2 employees start working on the job at the same time but, after 10 hours, one employee stops working and let the other one finish alone for another 10 hours.
Real Behavior - Finite Scheduling : situation #4 - (Operation assigned to a single resource)
Job #040185-1-1. The operation is assigned to a single resource this time :
The resource group only has 3 active resources :
The operation has a prod standard of 30 hours and 3 scheduling blocks :
Let’s run global shceduling in finite mode. Here is the result :
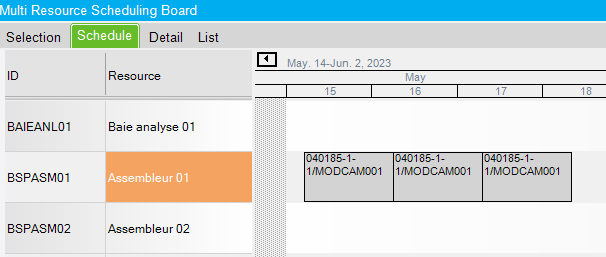
Our job was scheduled. The operation is divided in three 10 hours scheduling blocks. Since the operation is assigned to a single resource, all the scheduling blocks must be executed by this single resource. So, even if other resources were available, all the scheduling blocks were assigned consecutively by the engine.
The total man hours is still 30 hours and the lead time in this scenario is 30 hours.
Real Behavior - Finite Scheduling - Conclusion
Using scheduling blocks in finite scheduling means that the production time of the operation must be split equally in the specified number of blocks. Each of these blocks will be scheduled to available resources one after the other, indepedently. The behavior depends heavily on the resources load at the time when the split job is scheduled.
Real Behavior - Infinite Scheduling #1 (Operation assigned to a resource group)
For this first situation, we’ll come back with our first scenario but, this time, scheduled infinitely. Job #000973. The operation is assigned to a resource group :
The resource group has 2 active resources :
The operation has a prod standard of 30 hours and 2 scheduling blocks :
We run global scheduling in infinite mode. Here is the result :
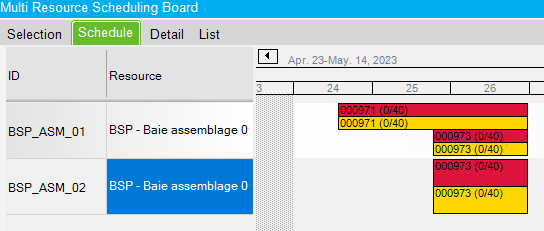
Just like the first scenario, job 000971 had a higher scheduling order, so it was scheduled first. It was assigned to the same resource group than our job 000973, so the first available resource (BSP_AMS_01) was assigned to its operation.
Then, job 000973 was scheduled. The operation is divided in two 15 hours scheduling blocks. Since we are scheduling infinitely, it doesn’t matter that ressource BSP_AMS_01 is loaded, so the two scheduling blocks are assigned at the same time on resource #1 and #2. The total man hours is 30 hours and the lead time is 15 hours.
Real Behavior - Infinite Scheduling #2 (Operation assigned to a resource)
We’ll repeat the previous scenario but this time the operation will be assigned to a single resource.
Resource group has 2 active resources :
Our operation has a prod standard of 30 hours and 2 scheduling blocks :
We lauch global shceduling in infinite mode:
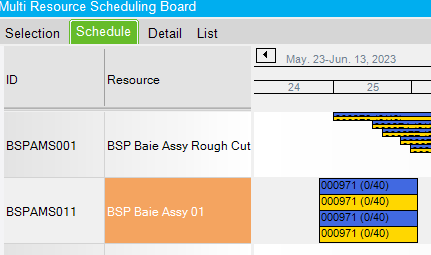
Since we are scheduling infinitely, it doesn’t matter if the resource is loaded. So, the engine can assign both scheduling block at the same resource at the same time. The total man hours is 30 hours and the lead time is 15 hours, even if one single resource is required
Real Behavior - Infinite Scheduling - Conclusion
Contrary to finite scheduling, using scheduling blocks in infinite scheduling will always split the lead time of the operation by the number of scheduling blocks since resource load is not considered. This behavior may not be wanted, as per the last example when we assigned the operation to be executed by a single resource.
A quick word about crew size
When assigning scheduling resources to an operation, there is a field down below labeled “crew size”
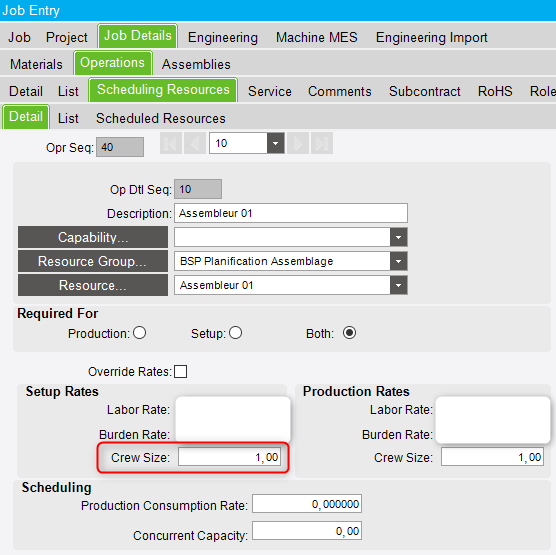
This field doesn’t have any impact on the scheduling engine. It is used for reporting and/or financial purposes.
Here is a real business problem
In our case (as for many manufacturer), we have workstations with mulitple employees. We want the lead time of the operation to be split by the number of employees. So, if my operation has a prod standard of 30 man hours and 3 people are working at the same time in the workstation, we want the lead time of the operation to be 10 hours.
Now that we know how the scheduling engine handles schedulig blocks, what would be the best approach ?
Well, if you can schedule infinitely, just assign the number of employees as the number of scheduling blocks.
If you want to schedule finitely, you have to find a way to stay clear of all the undesired behavior showed previously. The way to achieve this is the following :
1- Make sure that the resource group has the exact number of active resource as the number of employee in the workstation
2- Make sure that each and every job operation that is scheduled to this resource group has the number of scheduling blocks equal to the number of active resource.
This way, if all goes well, it should work.
Here’s the real problem : what if the number of employees assigned to the workstation changed ? Instead of 3, there are now only 2 employees assigned to the workstation.
Now, you have to not only update the resource group number of active resources, but the number of scheduling blocks of every single job operation assigned to this resource group. Good luck with that.
An idea of improvment
You know what would be great ?
First, add some kind of checkbox on the resource group level that would tell the scheduling engine, along with the “Split Operations” checkbox, that it must assign all the active resources of the resource group, at the same time, to a job operation.
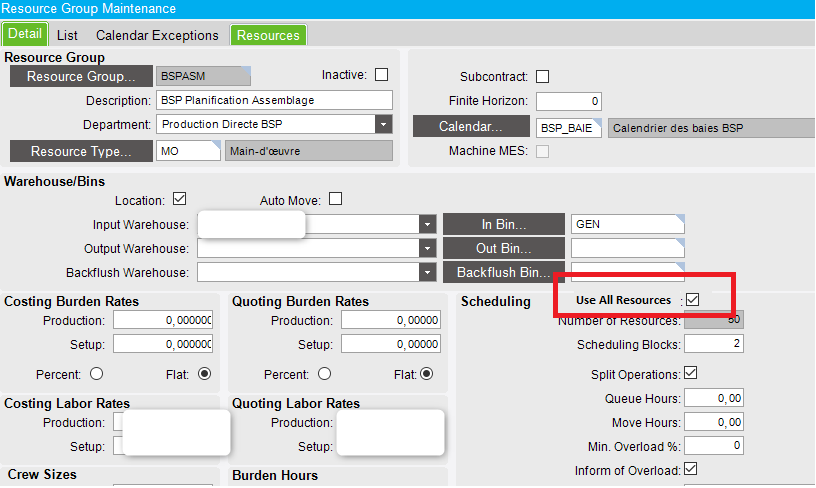
Also, when this checkbox is checked on the resource group level, the scheduling blocks fields on the job operation would be greyed out. The scheduling engine would split the operation in the exact number of scheduling blocks required to assign all the active resources of the resource group.
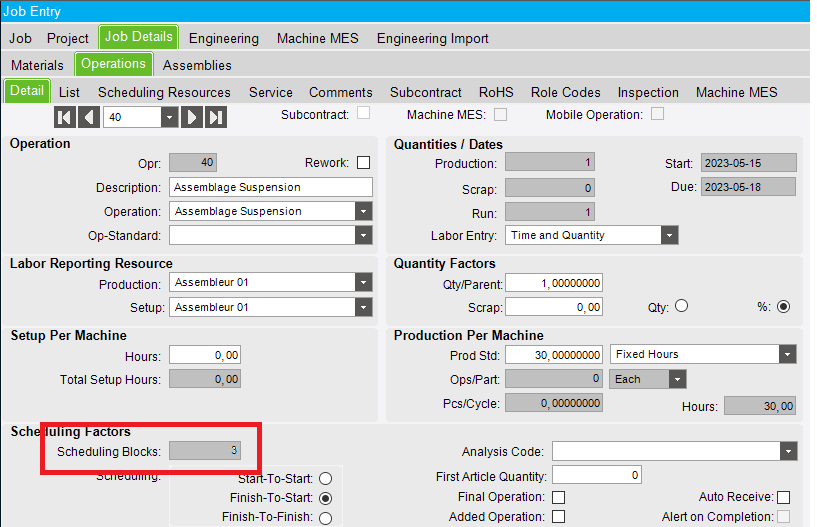
Something like that
End word
Please let us know if there is a mistake or anything in what was demonstrated, learning the scheduling engine is no easy task. I don’t know what I would have done without this forum, so thank you all.