Anyone using IDC to split and index off one barcode on the document you wish to file away?
We are trying to file away our receipt packing slips based on a barcode that our team will apply to it after they receive it. At the end of the day/shift they can set the stack of packing slips on the scanner and then IDC would separate individual packing slips, and index them, off the barcode mentioned above. For some reason ancora requires us to add a manual separator page in-between each packing slip. Is it just me or is this odd?
Here is what we heard from someone speaking to ancora:
“From what I’ve been able to find, it doesn’t look like we’d be able to utilize two barcodes on the same page. This would likely have to be two pages where the first page is the separator sheet only and the second has the barcode to capture/index. From there, you would need to set the barcode separation settings to “delete separator sheet” in Batch Type settings so that by the time it reaches Data Verify, the only page left for the document is the barcode for the receipt number.”
We don’t use Ancora for this, we straight up use ECM’s client and barcode scanning to bring in all of our Job Travelers and associated docs. Each is placed on the Ricoh MFC and sent to ECM using a button on the screen for PDF scanning to a folder. It works flawlessly when married to a workflow with a few datalinks to gather the info and attach it back to ERP.
ECM - we bought the barcode module/license for ECM, but only sort of use it like intended. Easier to show than explain, but here goes:
The ECM Client brings in the document from the folder being monitored - that is the drop point form the Ricoh MFC. This creates the new document in ECM of the JobTraveler content type. The Workflow then has the ‘read barcode’ step, and goes through a datalink to get info from ERP, and lastly attached it to the Job in ERP. Our processing on the floor allows for a traveler to be scanned as the job makes it to shipping, so we don’t do any bulk scanning. However I think it would work.
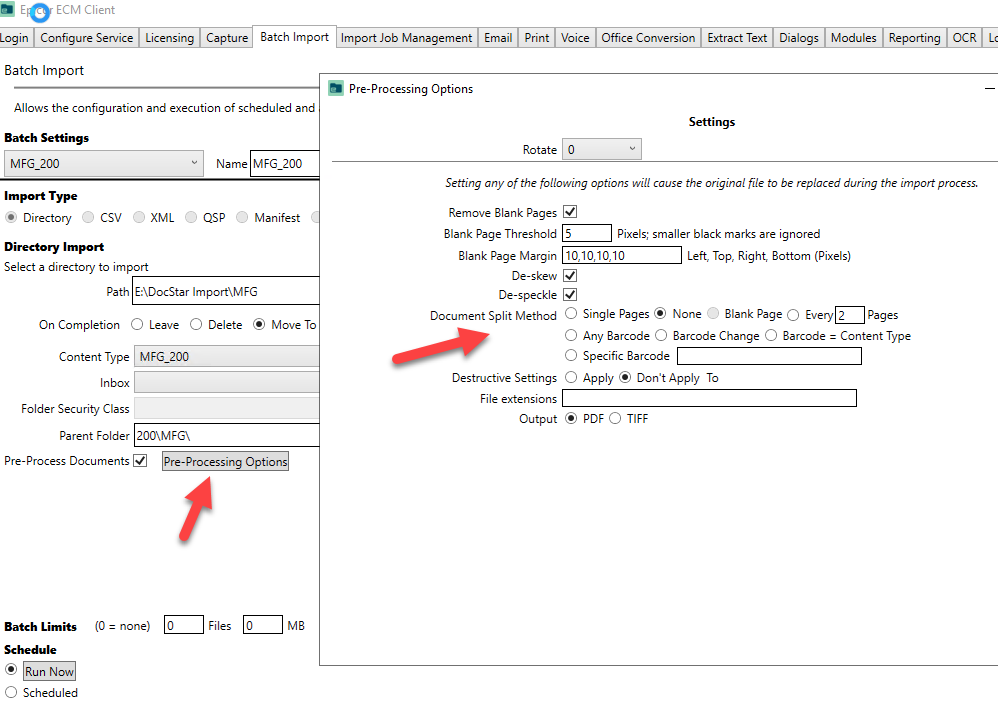
The following screen is where you can specify a combination of blank page/barcode detection rules which may be exactly what you need.
Mike thanks for showing me the screens . I need Epicor or someone to give me the yes or no answer to the question: can you set the whole stack of travelers on it and will it split them and attach them without having to add a separator page in-between?
Based on what you show I don’t know if it’s possible to avoid the blank page or separate page, is that what you would guess too?
What they did at the previous place, was put a “BREAK” barcode on the sales order, and it was always the first document related to the following documents.
Not a huge fan of batch processing myself. Sometimes it couldn’t read the barcode and the whole stack went to one order. I’d prefer whatever key be on each document and load them as they were made or scanned when complete. But that’s just cranky ole me…
@utaylor I also do this in ECM but without the barcode module using @MikeGross’s workflow as the starting point I tweaked it for us. We do use the HP separator page and scan them in one stack and they are split into PDFs that we drop into a folder for ECM. Even without the barcode which would likely get me to 100% I can get 90%+ with just OCR on the PO number and packslip. I do in in ECM since I am very protective of my IDC counts. Takes one person 10 minutes to fix the indexing in the ECM workflow for the day.
My fear of barcodes as a separator for documents I don’t control is much like @Mark_Wonsil’s one errant vendor barcode placement and I have a mess.
The other thing I didn’t like about batch processing is that we treated the old vanilla folder as the thing to store and not individual documents. Inevitably, when someone wants to see the traveler, they also have access to the invoice, which we prevented them from seeing in ERP.
One big pdf, one document type, one security group.
Couldn’t use document packages to see if a document was missing either.
Also, we had to manually file all the documents until they could be scanned, so they weren’t available in DocStar until after invoicing. Invoice was the worst because we printed it out - so we could scan it in the back in.
But that’s the way we’ve always done it… Yeah, not a fan of batch processing when I can avoid it.
@utaylor yes it does. To @Mark_Wonsil’s point it is not perfect. I changed the font and location of the PO on the inventory movement report to get the PO number to 100% and the packing slip from the receipt to 90%. If I had the barcode module I would have printed those barcodes on the report to OCR.
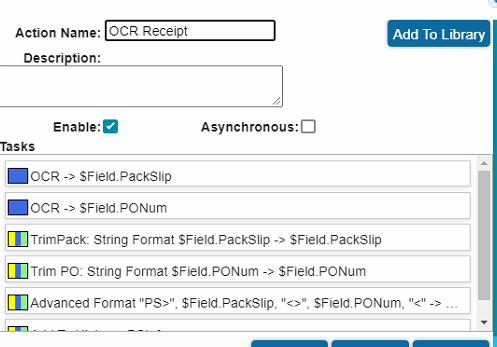
I changed @MikeGross’s workflow step Get PONum and Packslip to do OCR on these two fields.
Here is our process.
Stack receipts in this order. Movement report, customer documents, separate page.
Scan with HP scanner and use their utility to make individual PDFs
Copy those to an ECM monitored folder that sends them to the Packslip Import workflow. No preprocessing is done.
OCR for PONum and packslip number.
Check if that is a valid receipt.
If it matches then rename the pdf file with PO number and packslip and attach to receipt in Epicor.
If not it goes to a manual indexing to fix the packslip number, then attaches in Epicor.
95% of this is from @MikeGross’s workflow. I just made a few tweaks.
Thank you both @MikeGross and @gpayne for taking the time to take screenshots.
I am going to try and test the efficiency and accuracy of these three methods (they all are around a bulk import process):
IDC to split on a barcode and then use it’s OCR to read PO and packslip from a text field below the barcode
use ECM to do the same as approach #1 with the workflow you guys have (IDC not required).
ECM split and index off barcodes with barcode module.
Each approach has downsides with the IDC side costing more per page processed like you mentioned Greg. I don’t know how good ECM is at OCR and what caveats there are, like does the barcode need to be in the same place every time?
Anyways, I would love to stick with the bulk processing and splitting so that the person doesn’t have to get up and scan in every separate pack slip. Maybe I could just buy a scanner for every desk…
Thanks Greg, this whole automation thing is great, I just can’t believe the solution to automating splitting was adding in another manual step of inserting separator pages…
I’ve already seen 3 repos on github of how to split a file into many separate files on a barcode… you would think Ancora or ECM would have automated this step a little bit more, not added another manual process.