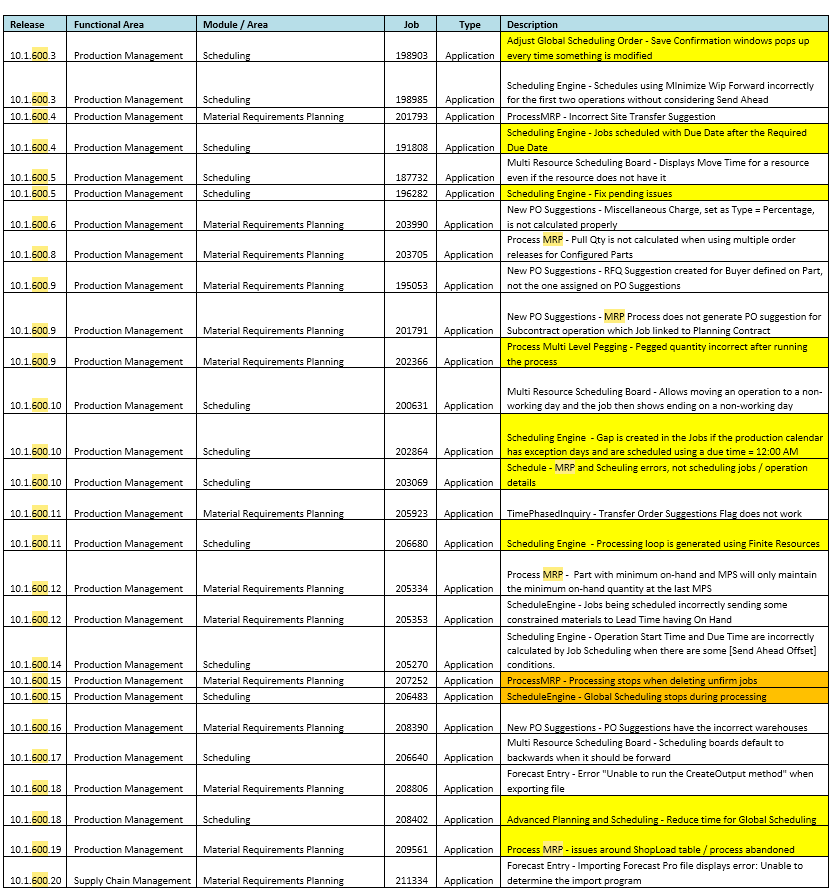
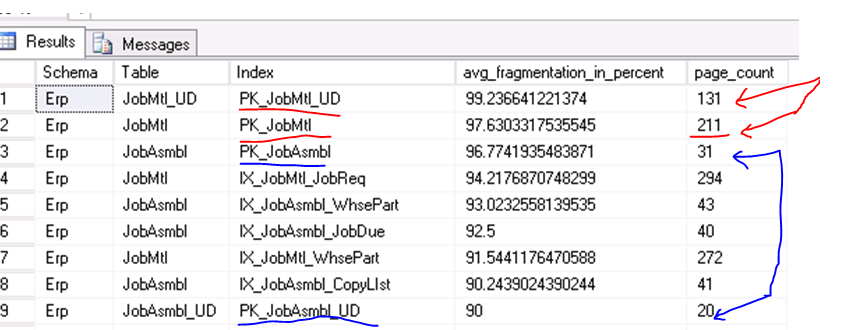
We are on Epicor 10.1.500.14 and in the last few weeks we’ve really been struggling with MRP. It’s gotten to the point where I log in every night, late in the evening to check on it, and folks here who depend on MRP are getting quite frustrated. And my old tricks (reboot all server (app and SQL database) force MRPRecalcNeeded = true on all parts and run net change, etc.) are not helping this time.
In an nutshell: if we try to run a Full Regeneration, more and more frequently it will bomb out on trying to delete the unfirm jobs:
23:45:04 ------------------------------------------------------------
23:45:04 Beginning of Delete Unfirm Jobs
00:45:05 Execution Timeout Expired. The timeout period elapsed prior to completion of the operation or the server is not responding.
The statement has been terminated.
00:45:05 The wait operation timed out
00:45:04 Execution Timeout Expired. The timeout period elapsed prior to completion of the operation or the server is not responding.
The statement has been terminated.
00:45:04 at System.Data.SqlClient.SqlConnection.OnError(SqlException exception, Boolean breakConnection, Action`1 wrapCloseInAction)
at System.Data.SqlClient.TdsParser.ThrowExceptionAndWarning(TdsParserStateObject stateObj, Boolean callerHasConnectionLock, Boolean asyncClose)
at System.Data.SqlClient.TdsParser.TryRun(RunBehavior runBehavior, SqlCommand cmdHandler, SqlDataReader dataStream, BulkCopySimpleResultSet bulkCopyHandler, TdsParserStateObject stateObj, Boolean& dataReady)
at System.Data.SqlClient.SqlCommand.FinishExecuteReader(SqlDataReader ds, RunBehavior runBehavior, String resetOptionsString, Boolean isInternal, Boolean forDescribeParameterEncryption, Boolean shouldCacheForAlwaysEncrypted)
at System.Data.SqlClient.SqlCommand.RunExecuteReaderTds(CommandBehavior cmdBehavior, RunBehavior runBehavior, Boolean returnStream, Boolean async, Int32 timeout, Task& task, Boolean asyncWrite, Boolean inRetry, SqlDataReader ds, Boolean describeParameterEncryptionRequest)
at System.Data.SqlClient.SqlCommand.RunExecuteReader(CommandBehavior cmdBehavior, RunBehavior runBehavior, Boolean returnStream, String method, TaskCompletionSource`1 completion, Int32 timeout, Task& task, Boolean& usedCache, Boolean asyncWrite, Boolean inRetry)
at System.Data.SqlClient.SqlCommand.InternalExecuteNonQuery(TaskCompletionSource`1 completion, String methodName, Boolean sendToPipe, Int32 timeout, Boolean& usedCache, Boolean asyncWrite, Boolean inRetry)
at System.Data.SqlClient.SqlCommand.ExecuteNonQuery()
at Erp.Internal.MR.MrpExp.deleteUnfirmJob(String vPlantList) in C:\_Releases\ERP\UD10.1.500.14\Source\Server\Internal\MR\MrpExp\MrpExp.cs:line 1966
at Erp.Internal.MR.MrpExp.main_block(List`1 ttMrpProcRows, List`1 ttMrpQueueRows) in C:\_Releases\ERP\UD10.1.500.14\Source\Server\Internal\MR\MrpExp\MrpExp.cs:line 2597
at Erp.Internal.MR.MrpExp.RunProcess(Int64 instanceTaskNum, String outputFileName) in C:\_Releases\ERP\UD10.1.500.14\Source\Server\Internal\MR\MrpExp\MrpExp.cs:line 945
00:45:04 The wait operation timed out
00:45:04 Unexpected Error - Cancelling MRP - MrpExp
00:45:07 Cancelling from MrpExp stopProcesses
Some sort of 60 minute timeout? But what would introduce this, we haven’t changed configuration of timeouts since going live on Epicor 10.1.500 almost 2 years ago now. And now this is happening like 50-80% of the time, but occasionally it will actually run okay, and often times the delete unfirm jobs step is actually more than an hour long and it works anyhow!? So, in an attempt to get around this, I’ll try running a Net Change MRP instead. Sometimes I can get this to go, but it is tough because I have to run it with a TON of processes or force some parts to NOT process MRP, because you see a bunch of this happening in the log file:
10:33:58 ------------------------------------------------------------
10:33:58 Starting sub-processes
10:33:58 Scheduling Jobs...
10:33:59 Building Non-Part List
10:34:09 Building PartList Level: 0-0
10:35:40 Process 4 not responding. Abandoned during process 'Defunct : Processing Part~4447601'
10:38:41 Process 1 not responding. Abandoned during process 'Defunct : Processing Part~4468012'
10:38:41 Process 2 not responding. Abandoned during process 'Defunct : Processing Part~4048401-40R'
10:38:41 Process 3 not responding. Abandoned during process 'Defunct : Processing Part~4448401'
The hardware hasn’t changed in at least a year as well, other than the virtual machines getting a little notch up in vCPU / RAM count awhile back to try to increase performance a bit. And this is not lame hardware - we’re talking Intel P3700 NVMe SSD for storage, etc.
Here are the full main log files in case the run parameters might be important:
MRP_NetAfterReboot_.log.txt (24.5 KB)
One of the processes that choked right away (two runs in here): MRP_NetAfterReboot_004.log.txt (32.4 KB)
MRP_Friday_.log.txt (13.5 KB)